Open problems in intercurrent-event handling and missing-data mechanisms in randomised clinical trials
A simulation-based assessment of the regulatory toolkit
2026-06-12
1.2 The regulatory arc
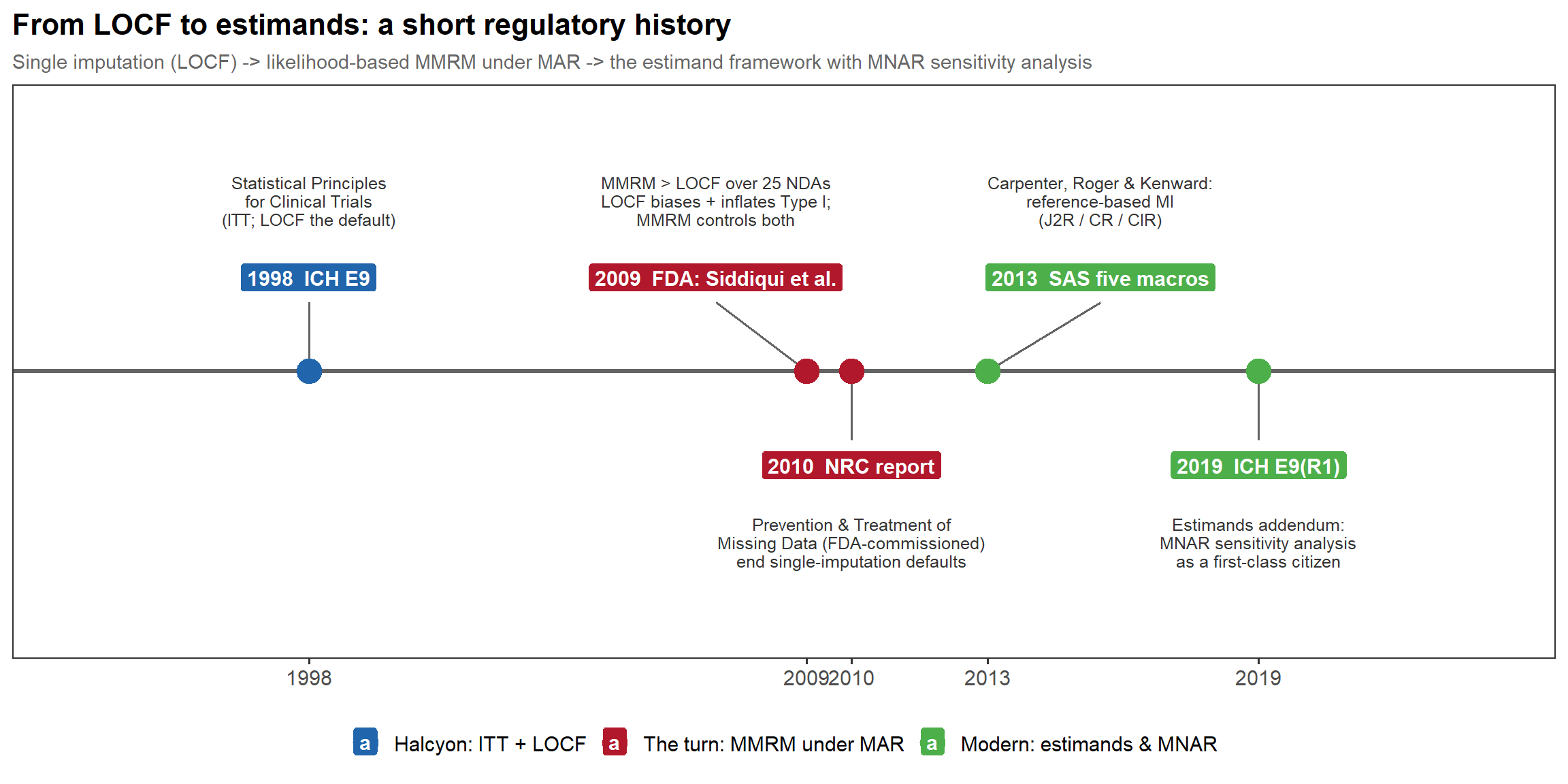
In words: single imputation (LOCF) gave way to likelihood-based MMRM under MAR — pushed by the FDA’s Siddiqui–Hung–O’Neill 2009 review of 25 NDAs and the FDA-commissioned NRC 2010 report — then to the reference-based MI five macros (Carpenter, Roger & Kenward 2013; James Roger / GSK for the DIA working group), and on to the ICH E9(R1) estimand addendum of 2019, which makes MNAR sensitivity analysis a first-class citizen.
2.3 The generating covariance
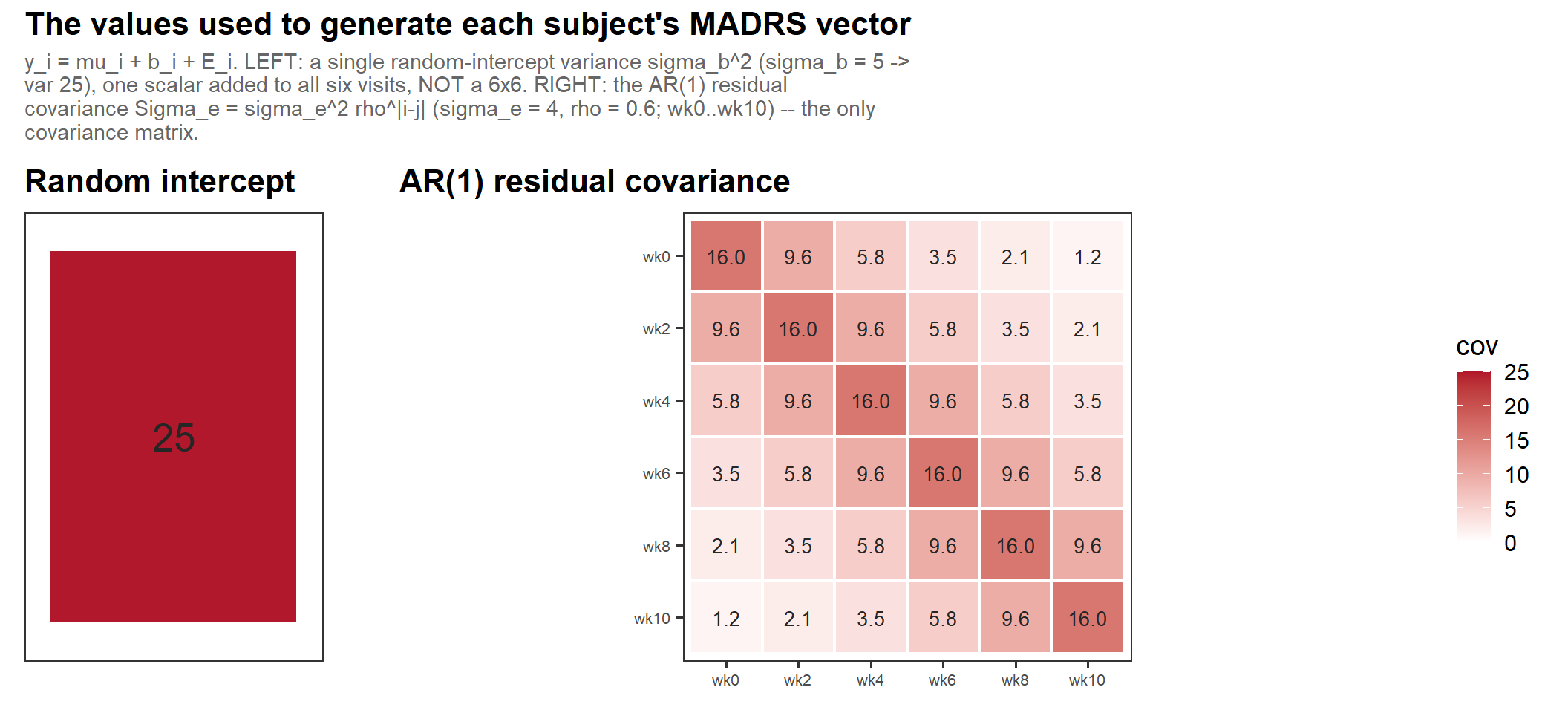
In words: the only covariance matrix in the generation is the AR(1) residual \(\Sigma_e\) (right, \(\sigma_e = 4\), \(\rho = 0.6\)); the random intercept is a single variance \(\sigma_b^2\) (left, \(\sigma_b = 5 \to 25\)) added on top — so the marginal within-subject covariance is simply their sum, \(\sigma_b^2 + \Sigma_e\).
3.2 Diggle–Kenward selection (cont’d)
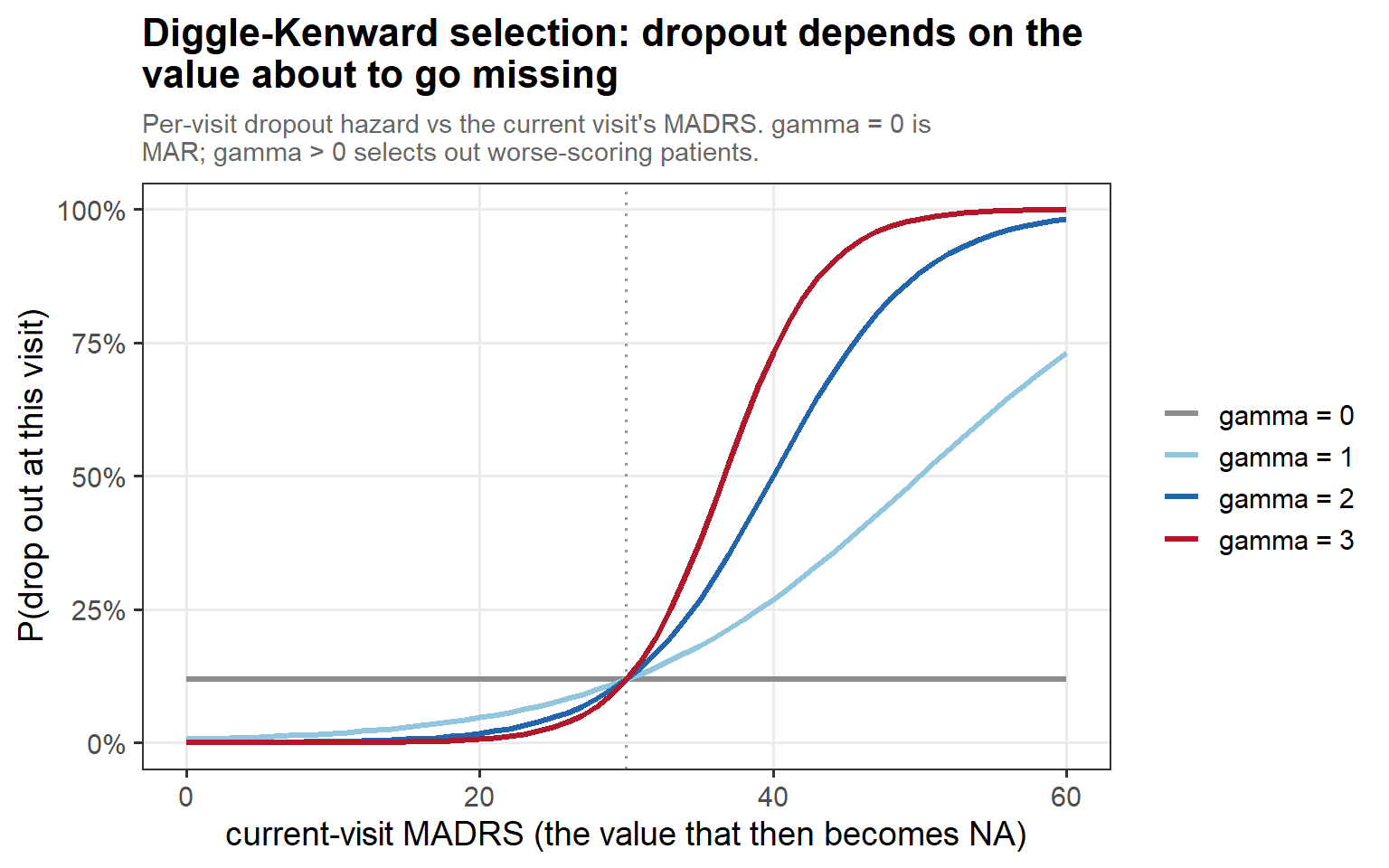
In words: the per-visit dropout hazard rises with the current MADRS, and γ sets the slope — γ = 0 is flat (pure MAR), while γ > 0 selectively pushes out the patients who are about to worsen.
3.2 Selection, in motion
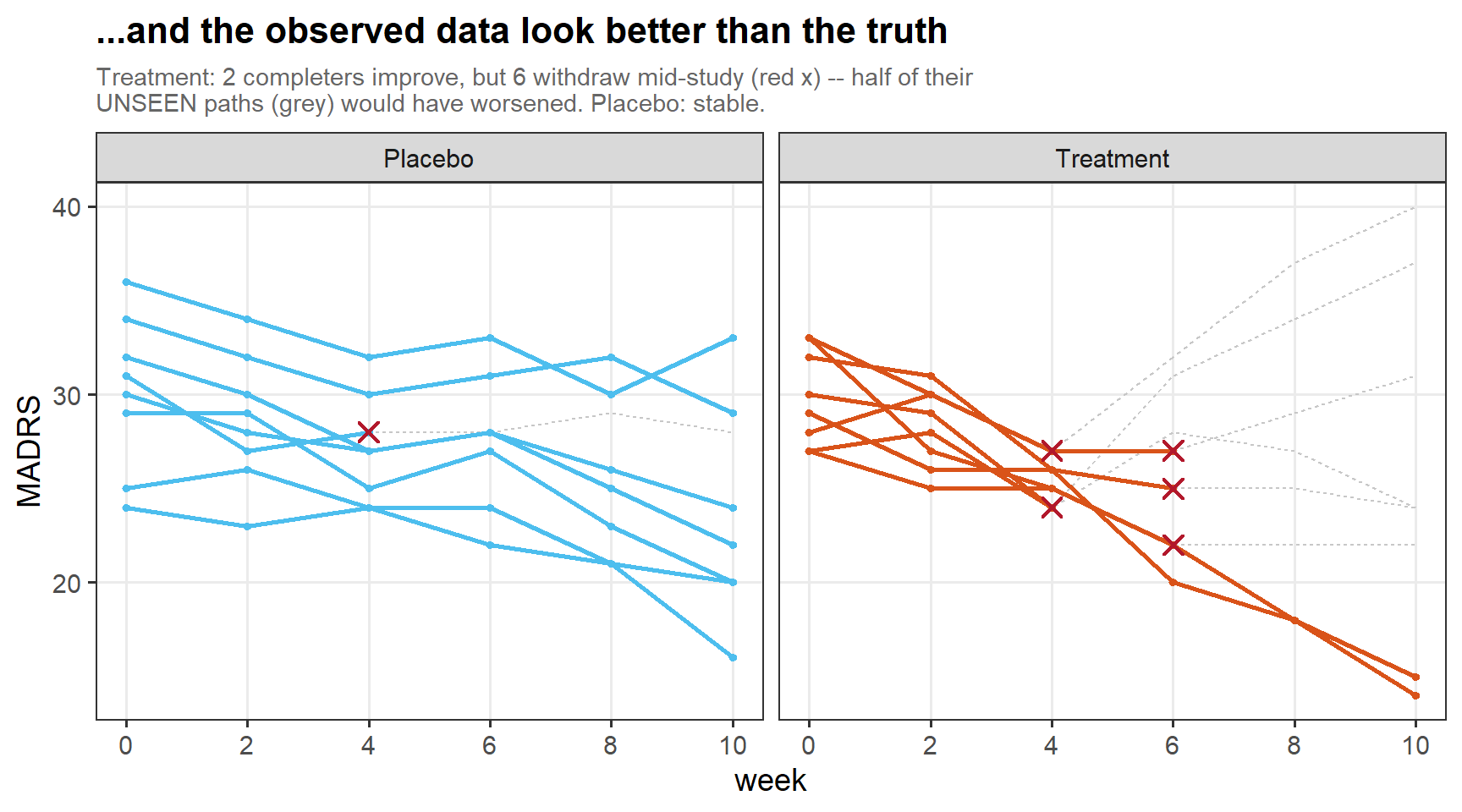
In words: Exaggerated example — the patients who stay are already improving, while those who leave are pulled out exactly as their own paths turn upward. Also their subsequent trajectory is another important but differently parametered story.
3.4 Two flavours of missingness (cont’d)
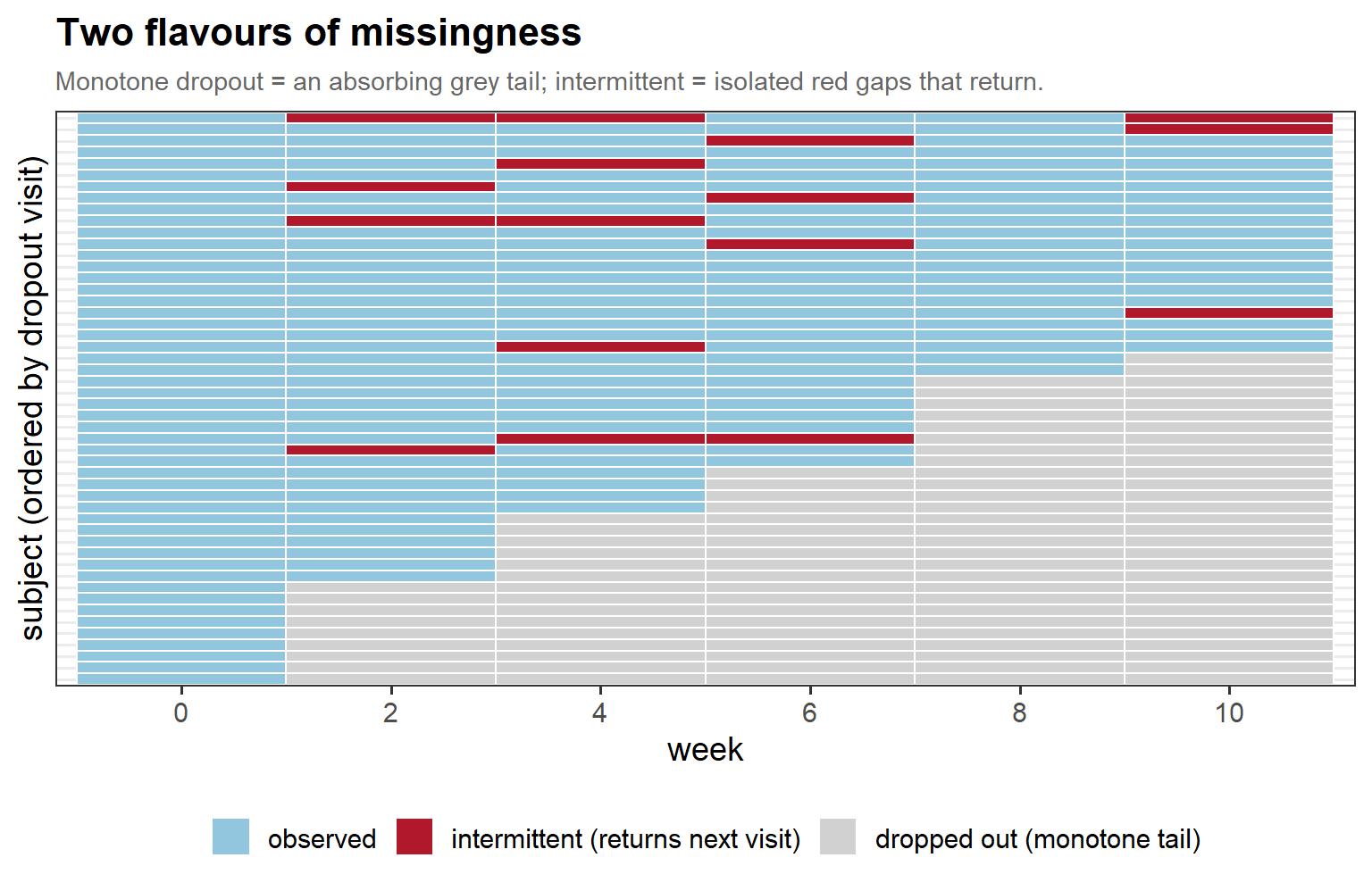
In words: monotone dropout leaves one absorbing tail of missing visits, while intermittent missingness punches isolated gaps into an otherwise complete record — and it is the latter that makes the δ-scope choice consequential.
3.5 Survivor bias (cont’d)
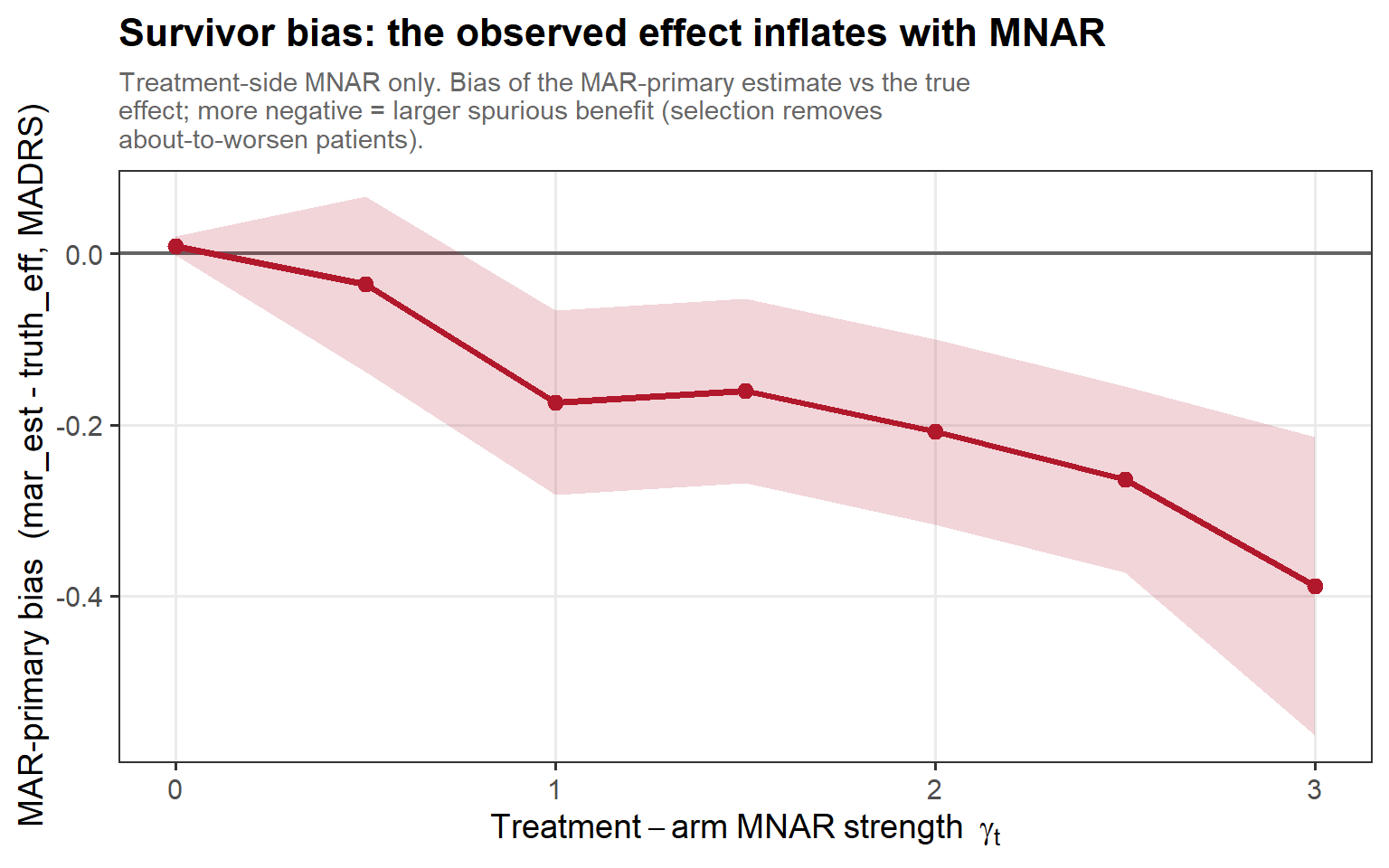
In words: as the treatment-side MNAR strength γ_t grows, the survivors get more favourably selected and the MAR primary overstates the treatment effect ever more — a bias built entirely from who remained.
3.6 Null inflation (cont’d)
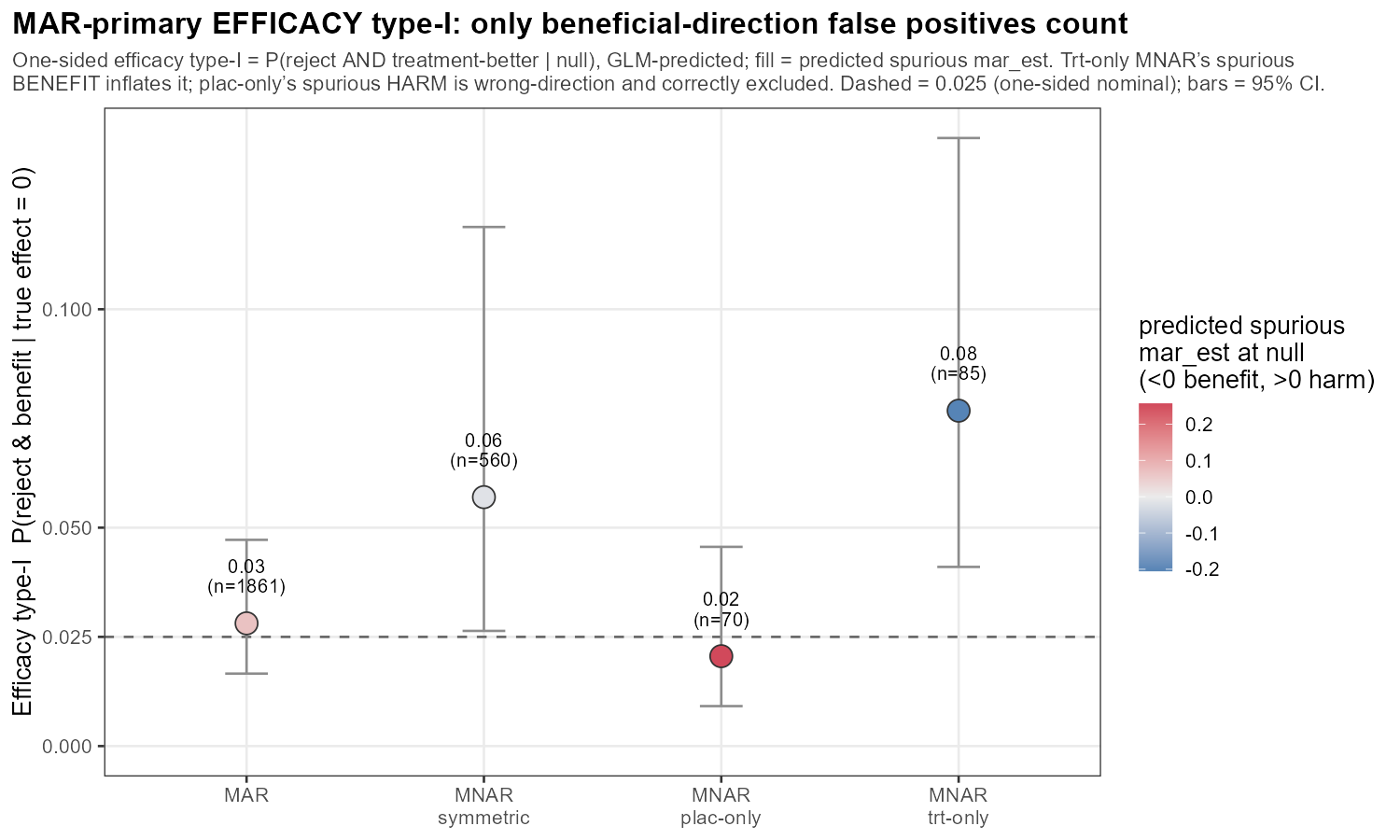
In words: the one-sided efficacy type-I — P(declare benefit | true null), nominal 0.025 (dashed) — holds near nominal under MAR and symmetric MNAR, and is inflated to ~0.08 only by treatment-side MNAR (spurious benefit); placebo-side MNAR makes a spurious harm, the wrong direction, and is correctly not counted.
3.6 Null inflation (cont’d)
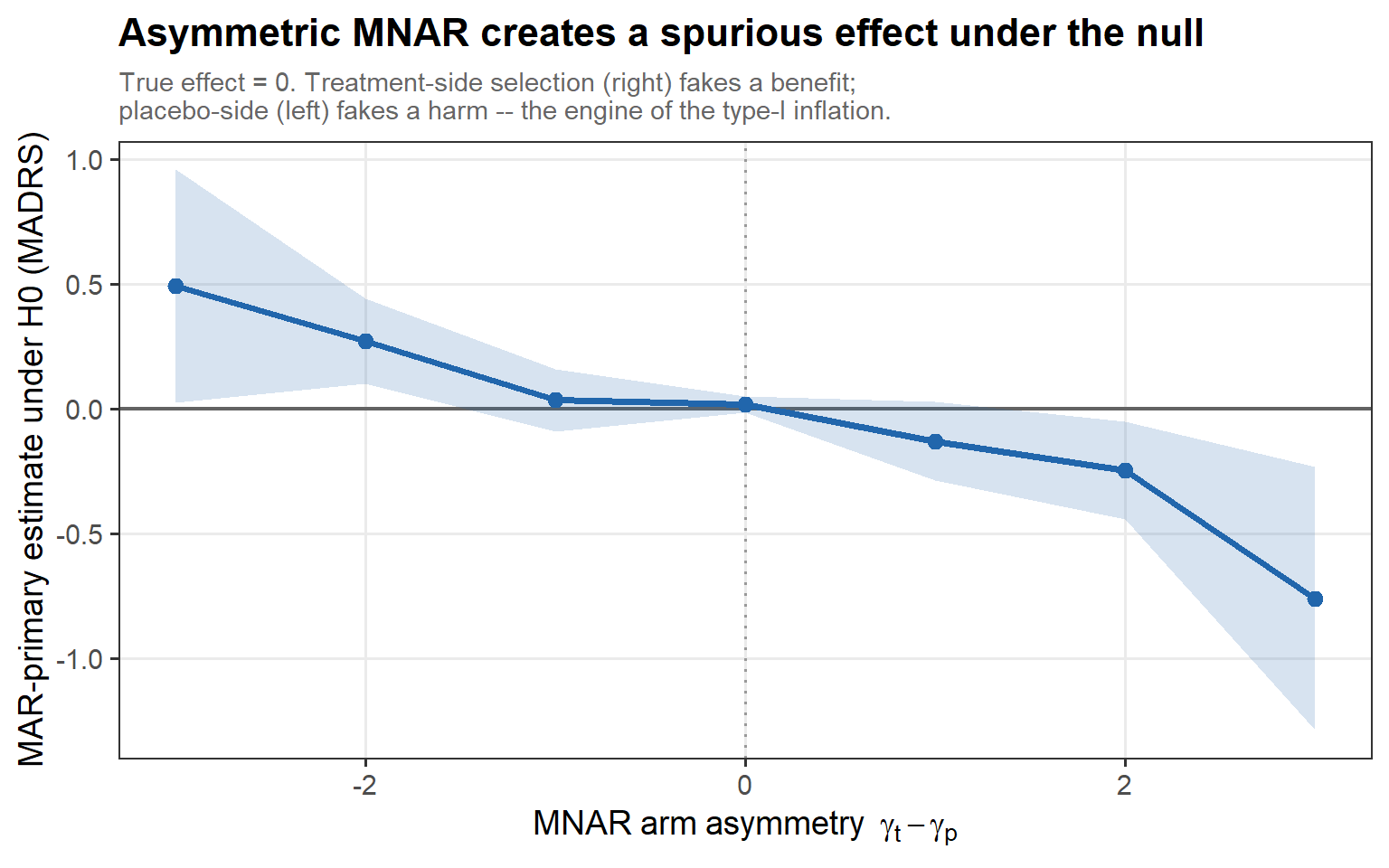
In words: under the true null the estimate drifts with the arm asymmetry γ_t − γ_p — treatment-side MNAR manufactures a spurious benefit, placebo-side a spurious harm. Asymmetric selection conjures an effect out of nothing.
3.7 J2R is one choice among five
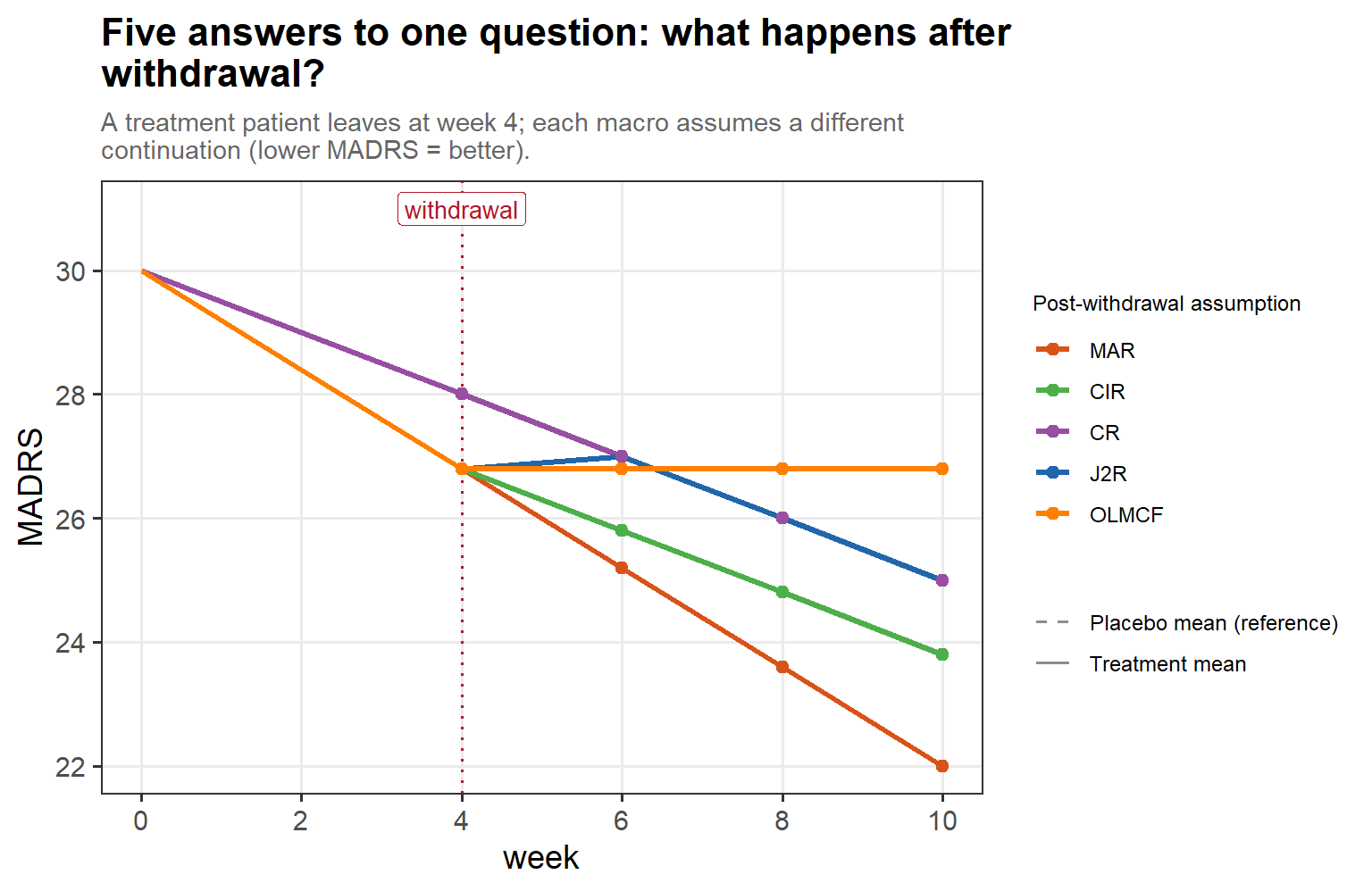
3.7 J2R optimism (cont’d)
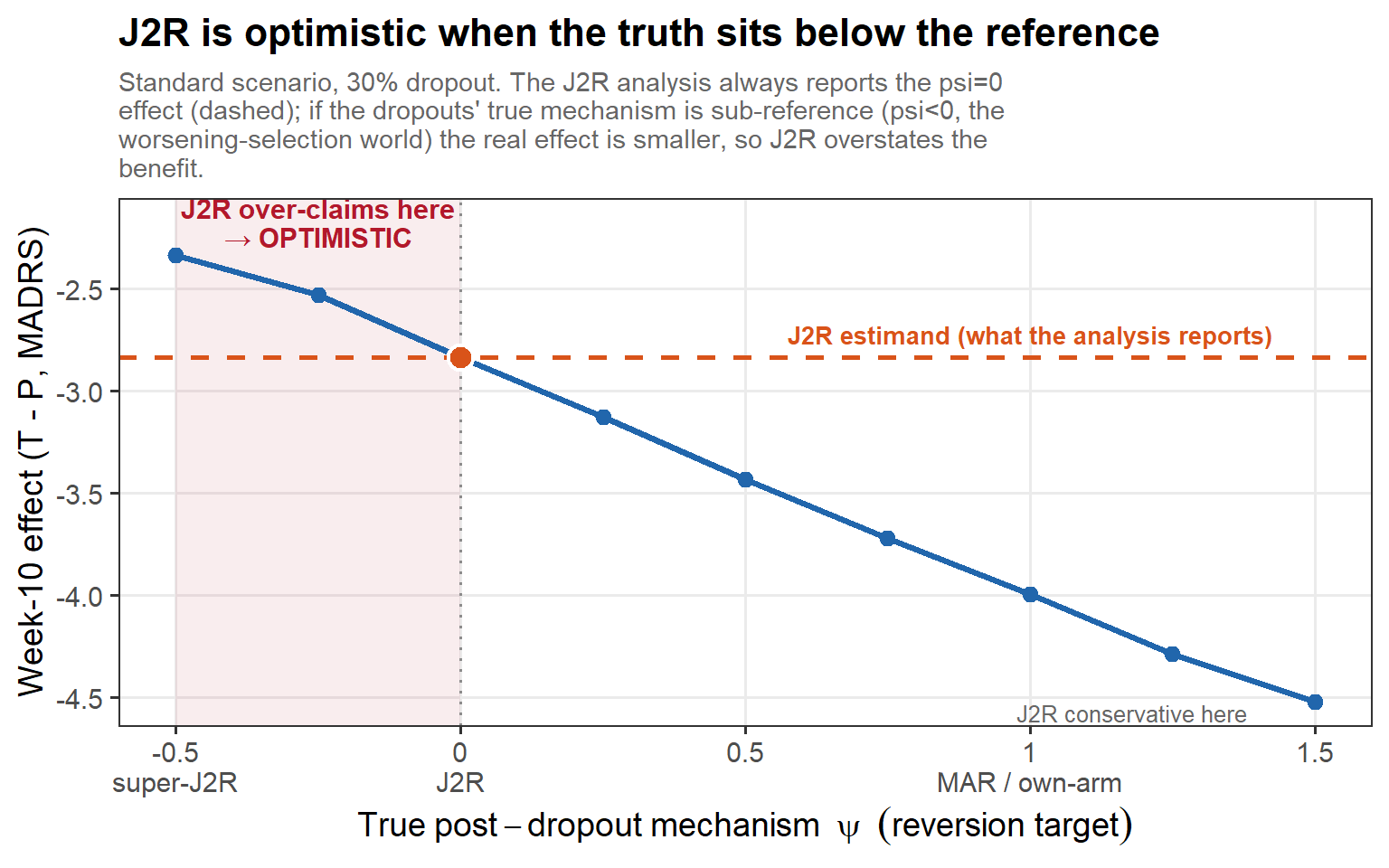
In words: the J2R analysis always reports the reference-reversion effect (the dashed line, ψ = 0). But the true mechanism is whatever nature picks: when selection pulls the dropouts below the reference (ψ < 0, red zone) the real effect is weaker than J2R claims — so J2R is optimistic, not conservative. Only when the truth leans toward own-arm continuation (ψ → 1) is J2R genuinely conservative.
4.2 The five macros
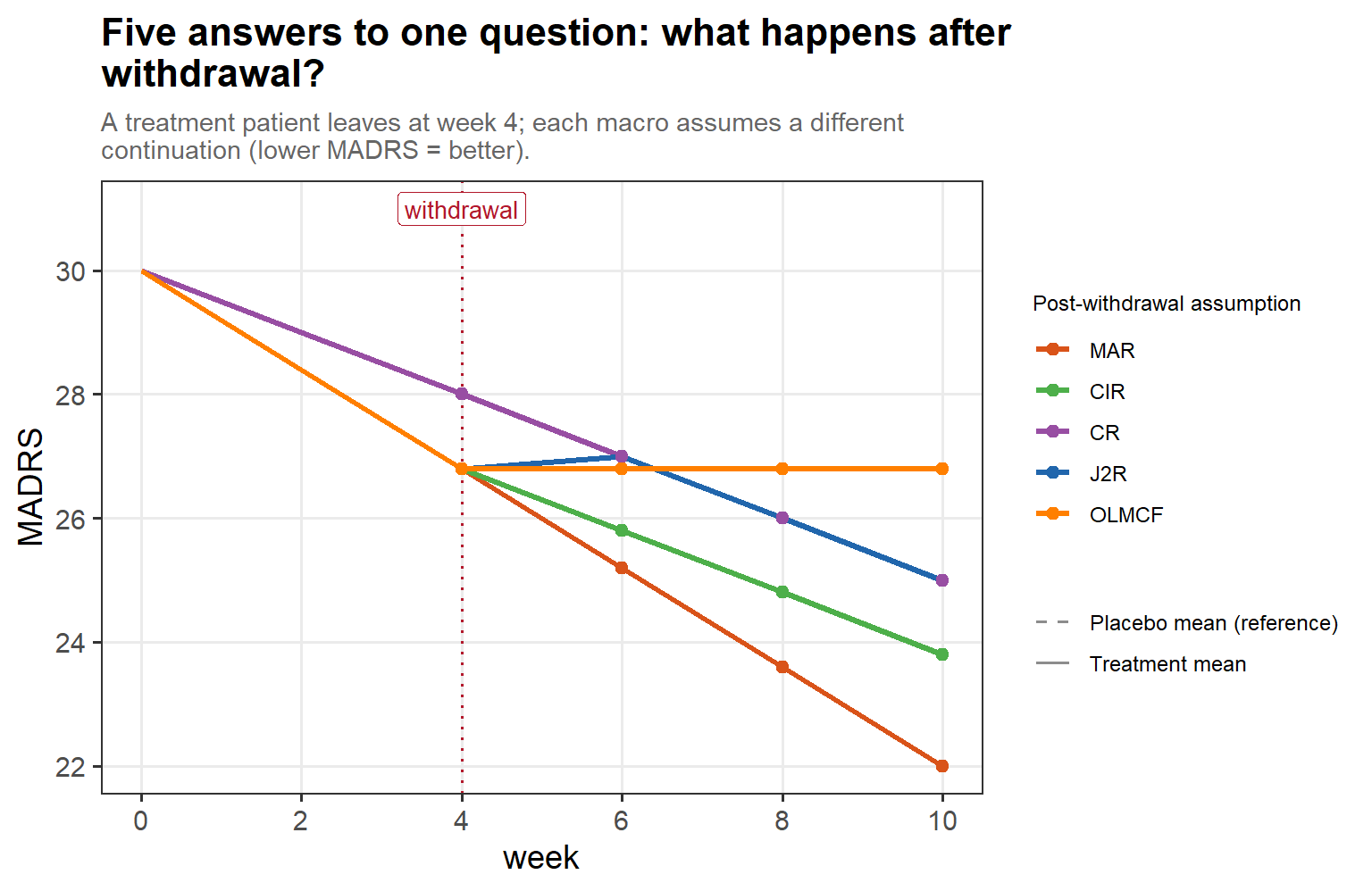
In words: a treatment patient leaves at week 4, and each of the SAS five macros tells a different story about what comes next — MAR keeps following the treatment mean, J2R jumps straight to the placebo (reference) trajectory at withdrawal, CR copies the reference throughout, CIR copies the reference’s increments from the withdrawal value, and OLMCF freezes the last observed value.
4.4 Same data, five estimands
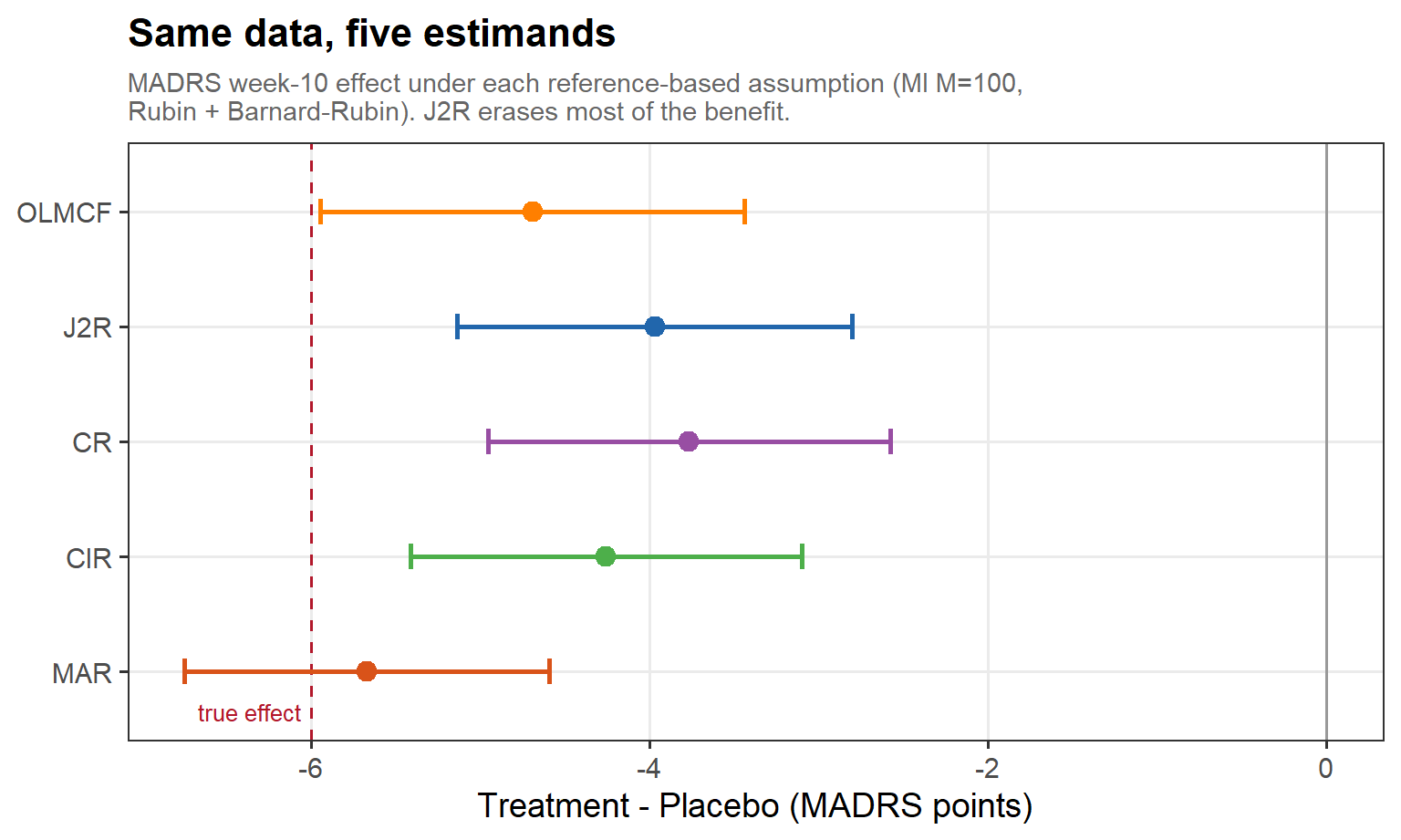
In words: the week-10 treatment effect on one dataset, re-imputed under each assumption (multiple imputation, M = 100, pooled by Rubin + Barnard–Rubin) — MAR recovers essentially the full benefit, while J2R erases most of it; the spread between the points is the sensitivity of the conclusion to an assumption we cannot check.
5.1 What coverage asks of us (cont’d)
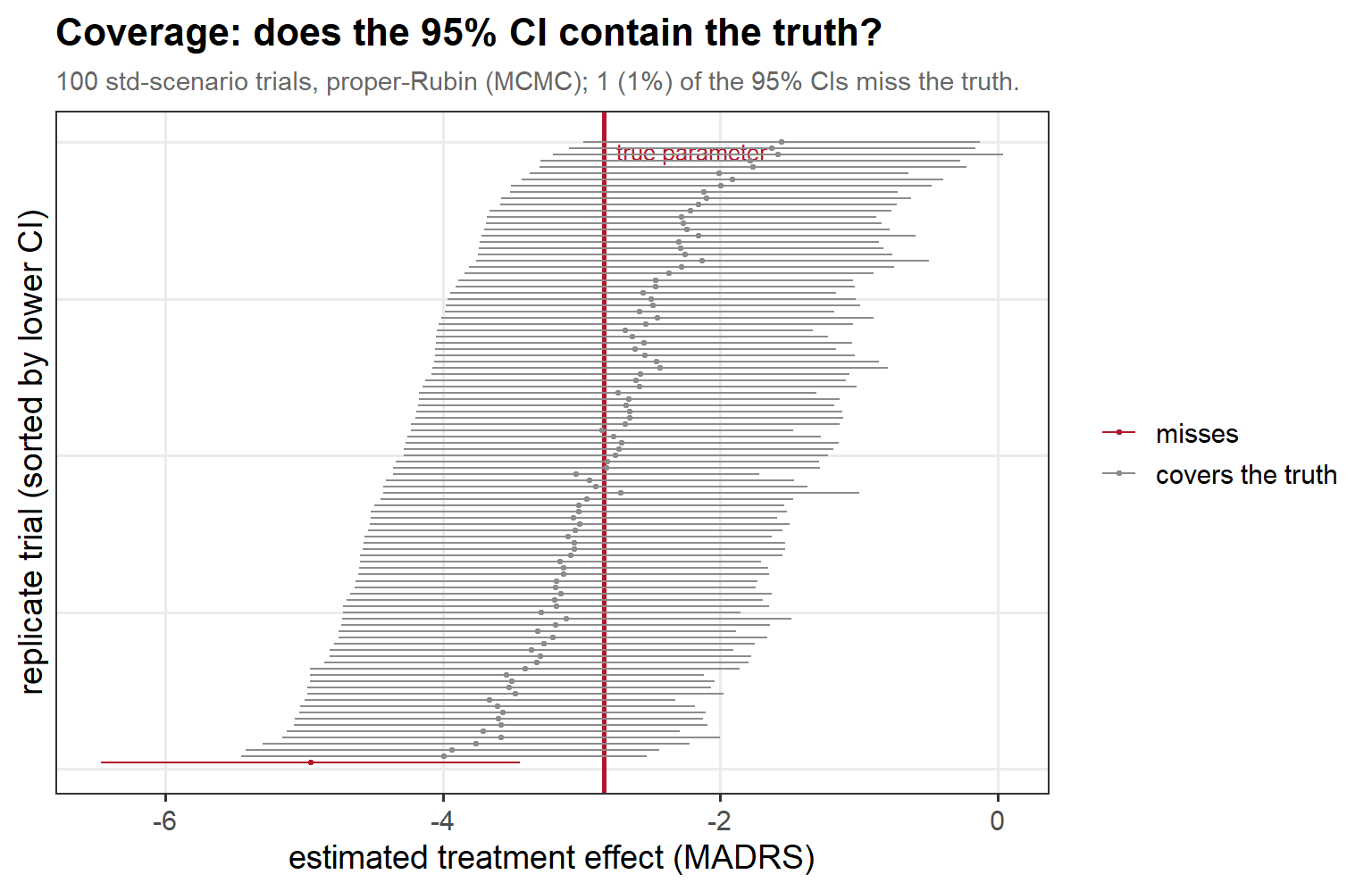
In words: each horizontal bar is one trial’s 95% CI from the standard scenario, sorted by lower bound; the red line is the true parameter, and the red bars that fail to cross it are the misses. A perfectly calibrated 95% interval misses about 1 in 20 — only a percent or two do here, a first hint that the featured method runs slightly conservative.
5.2 The two variance camps (cont’d)

Left, red: Frequentist (Bartlett, von Hippel, Lu) Right, blue: Information-anchored (Cro, Carpenter & Kenward)
5.3 Coverage at the standard scenario
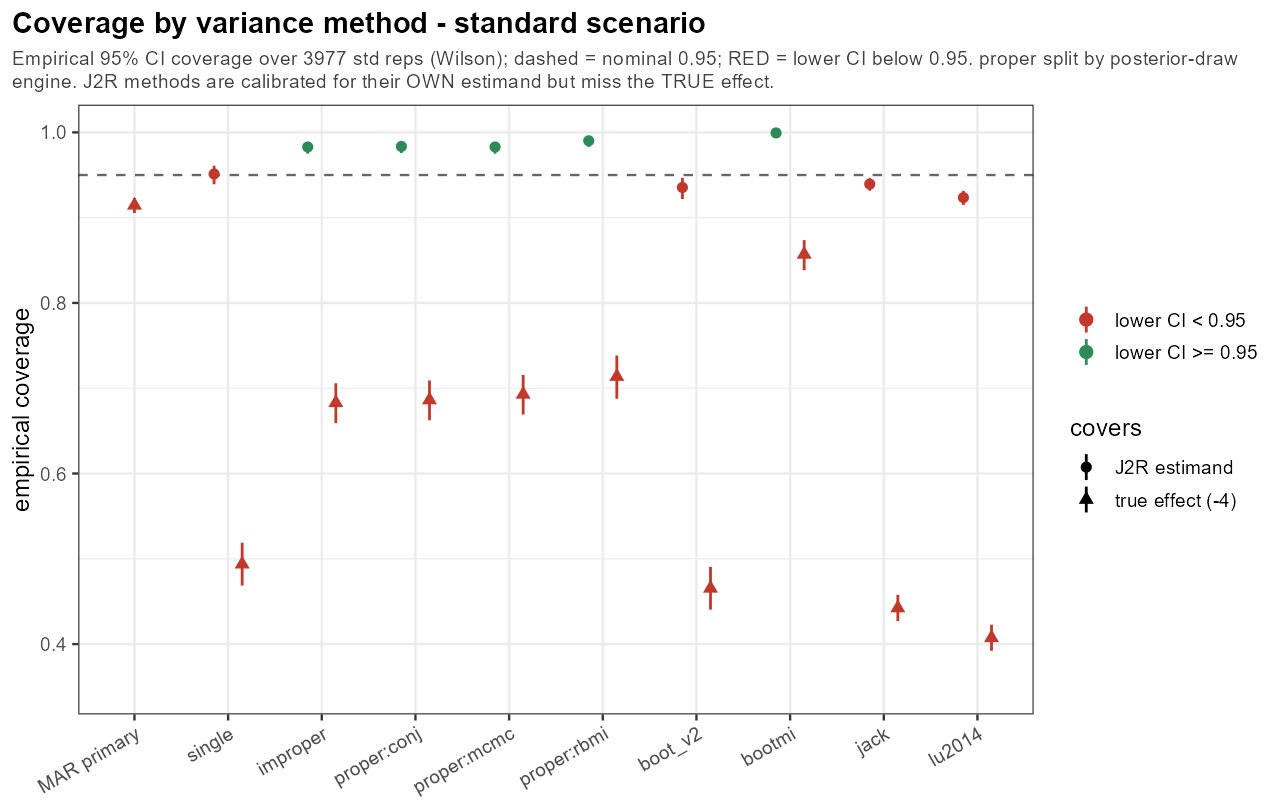
In words: each J2R method covers its own (J2R) estimand far better than the true effect — the information-anchored ones essentially nail it (~0.98), the frequentist ones fall a little short — yet all of them badly miss the true effect; under MAR there is no real dropout-driven shift, so J2R is simply aiming at the wrong target.
5.4 Frequentist variance shrinks with missingness (cont’d)
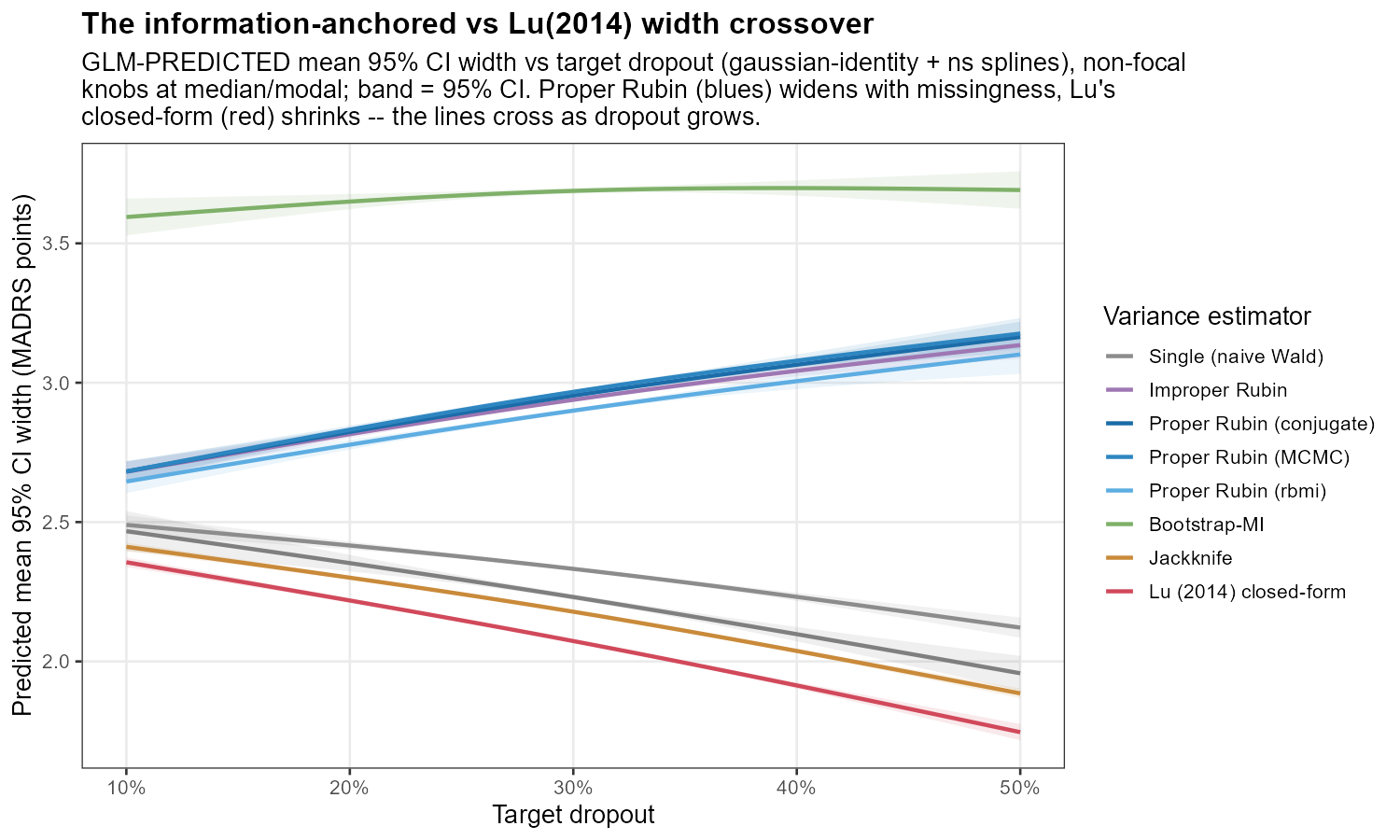
In words: as the missing fraction grows the frequentist (Lu-style) width bends downward while the information-anchored width holds; the two curves cross, and the widening gap to their right is precisely the over-coverage we reach in §5.9.
5.6 One knob: asymmetric MNAR
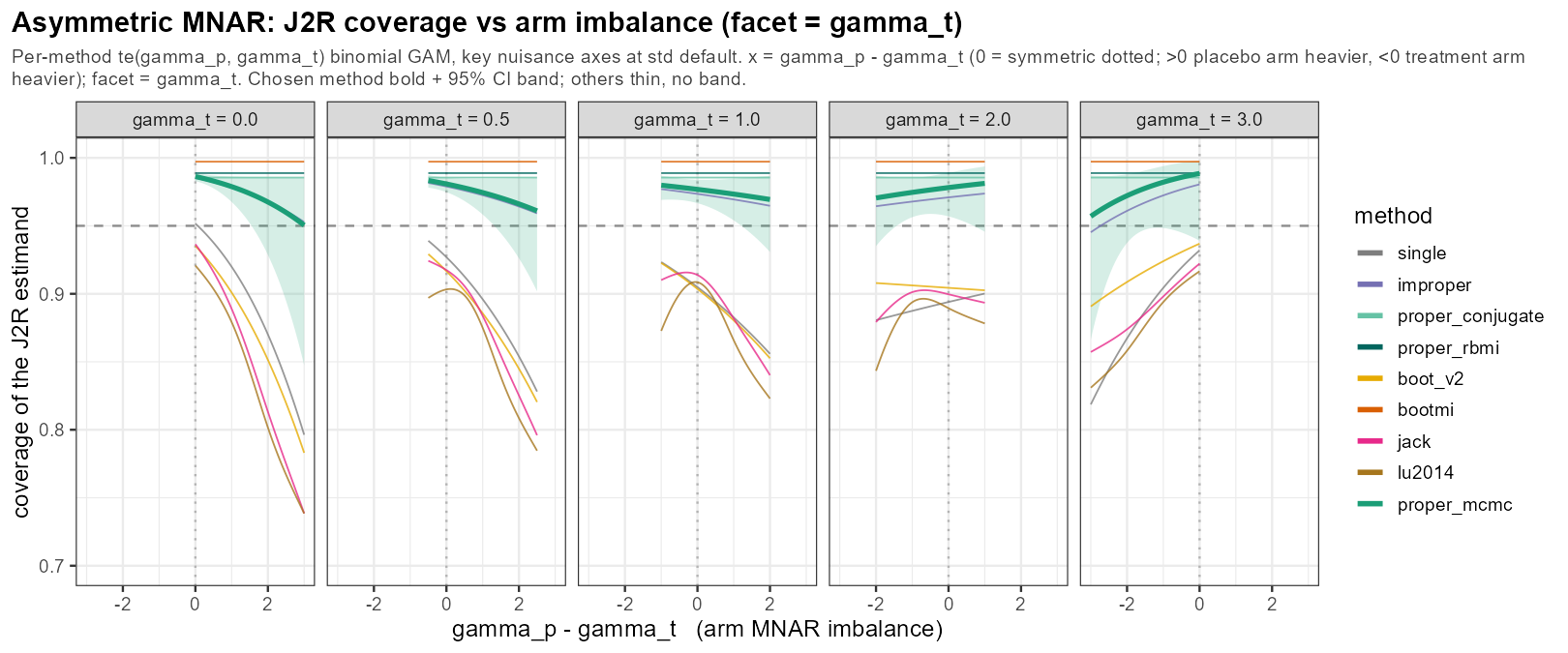
In words: when the two arms drop out for different reasons — asymmetric MNAR — the frequentist intervals degrade the hardest, while the information-anchored ones largely hold; this arm imbalance is the sweep’s sharpest stressor for the frequentist camp. (Note: this is a misnomer, we are turning two knobs at a time.)
5.6 One knob: the true mechanism
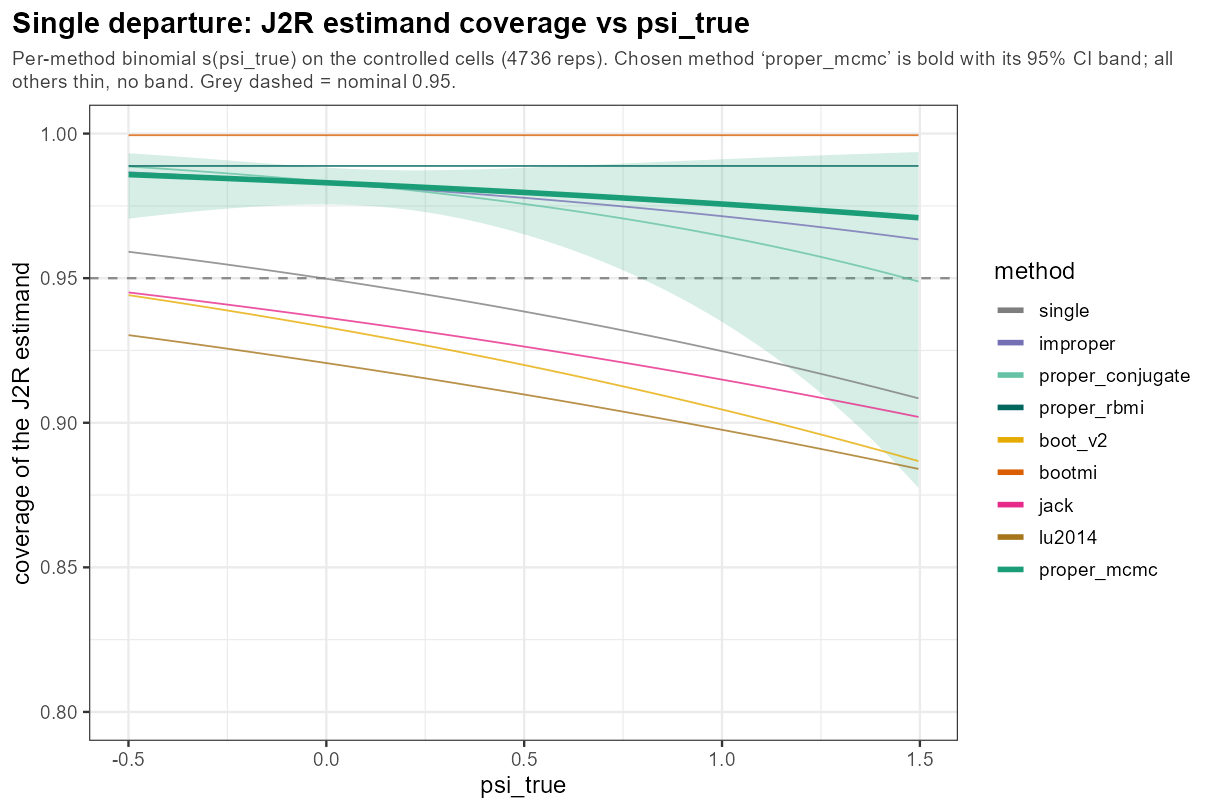
In words: sliding the true post-dropout mechanism away from J2R steadily erodes coverage — the method is calibrated only at the assumption it was built on, and pays for every step nature takes away from it.
5.6 One knob: sample size
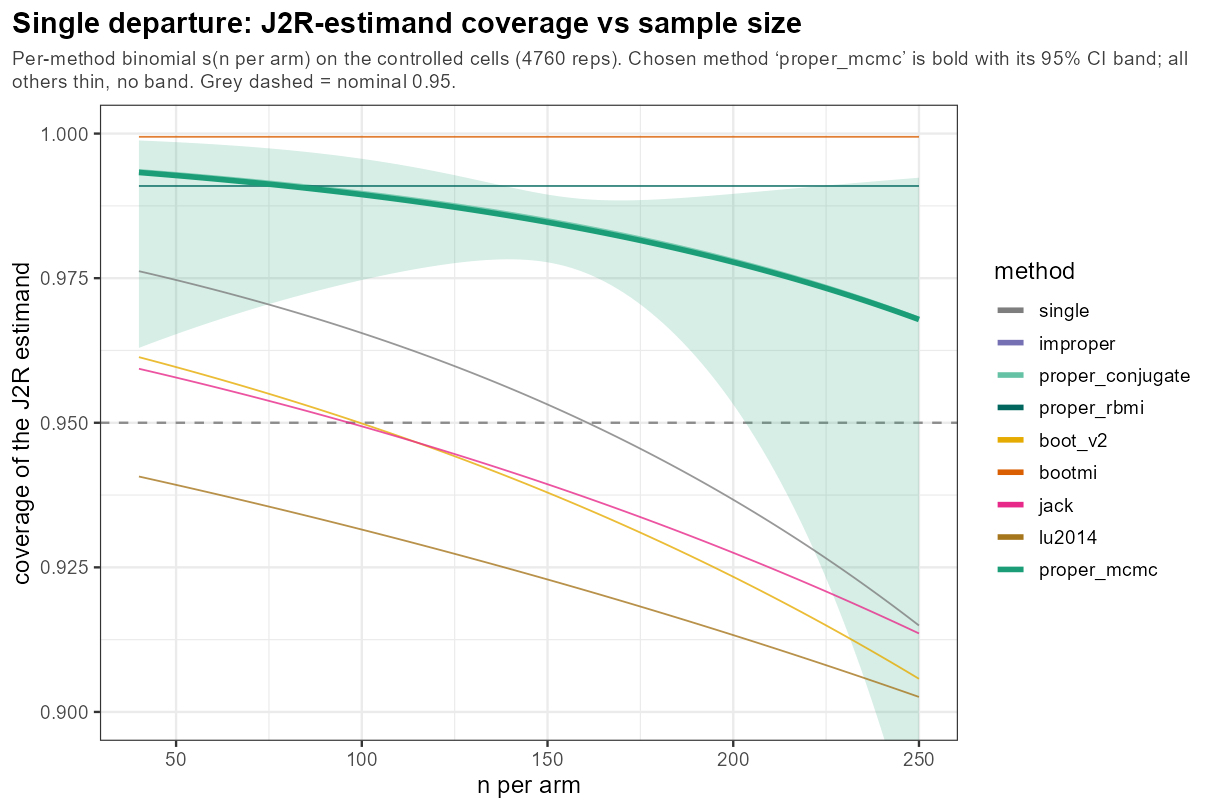
In words: as n per arm grows the J2R-estimand coverage holds its line near 95%, while true-effect coverage drifts downward — a larger trial buys precision around the J2R target, not around the effect a clinician cares about.
5.6 One knob: true effect
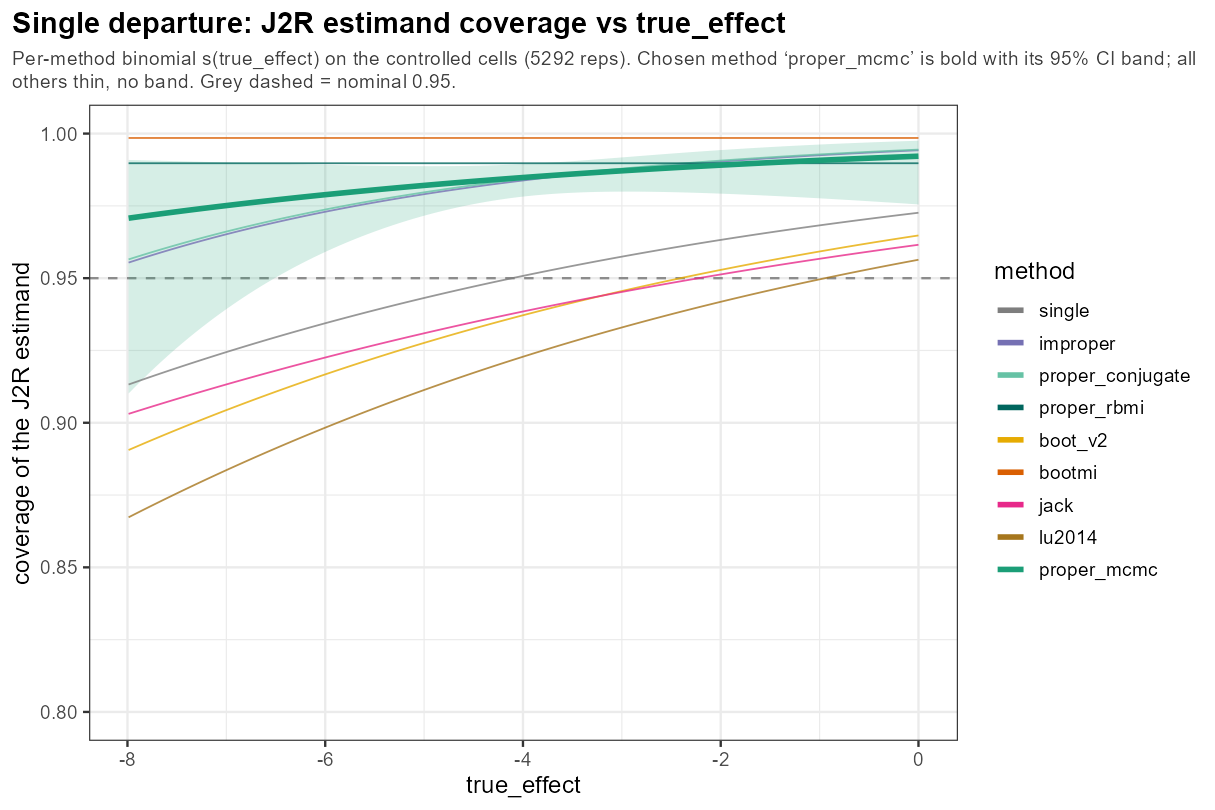
In words: sweeping the true week-10 effect from null to −8 leaves the coverage pattern unmoved — information-anchored methods near/above 0.95, frequentist a little short — so effect size alone is not a coverage stressor.
5.6 One knob: baseline severity
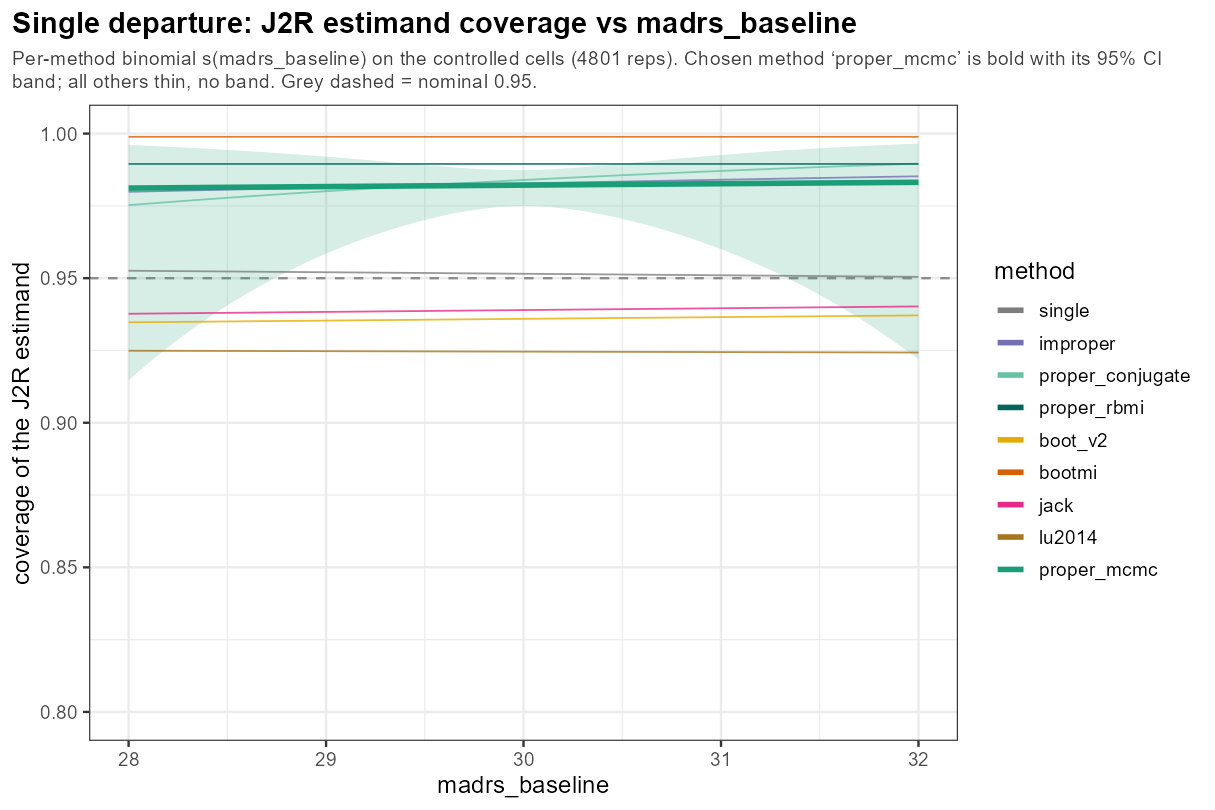
In words: baseline MADRS across its clinically plausible 28–32 band leaves coverage flat — a benign knob, with every method holding its place.
5.6 One knob: placebo slope
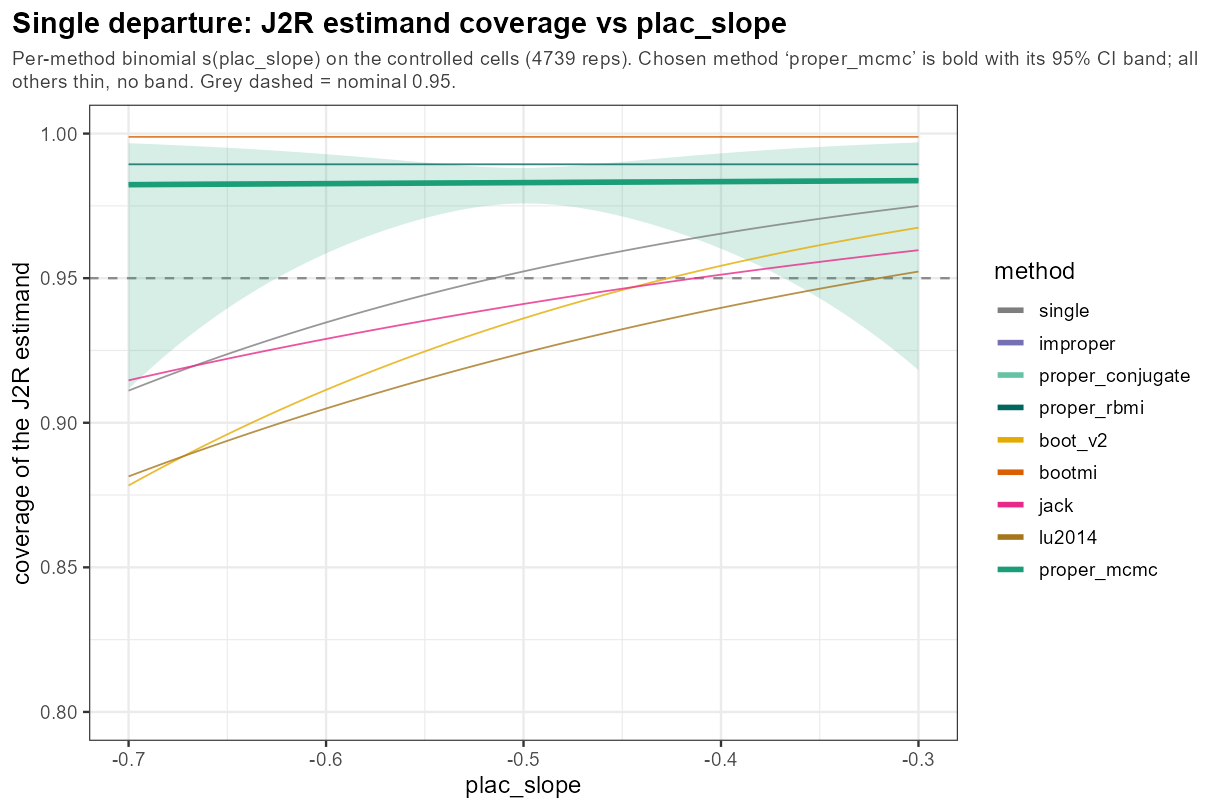
In words: the placebo-arm slope — how fast the reference itself improves — barely moves coverage; the method ordering is unchanged across its range.
5.6 One knob: between-subject SD
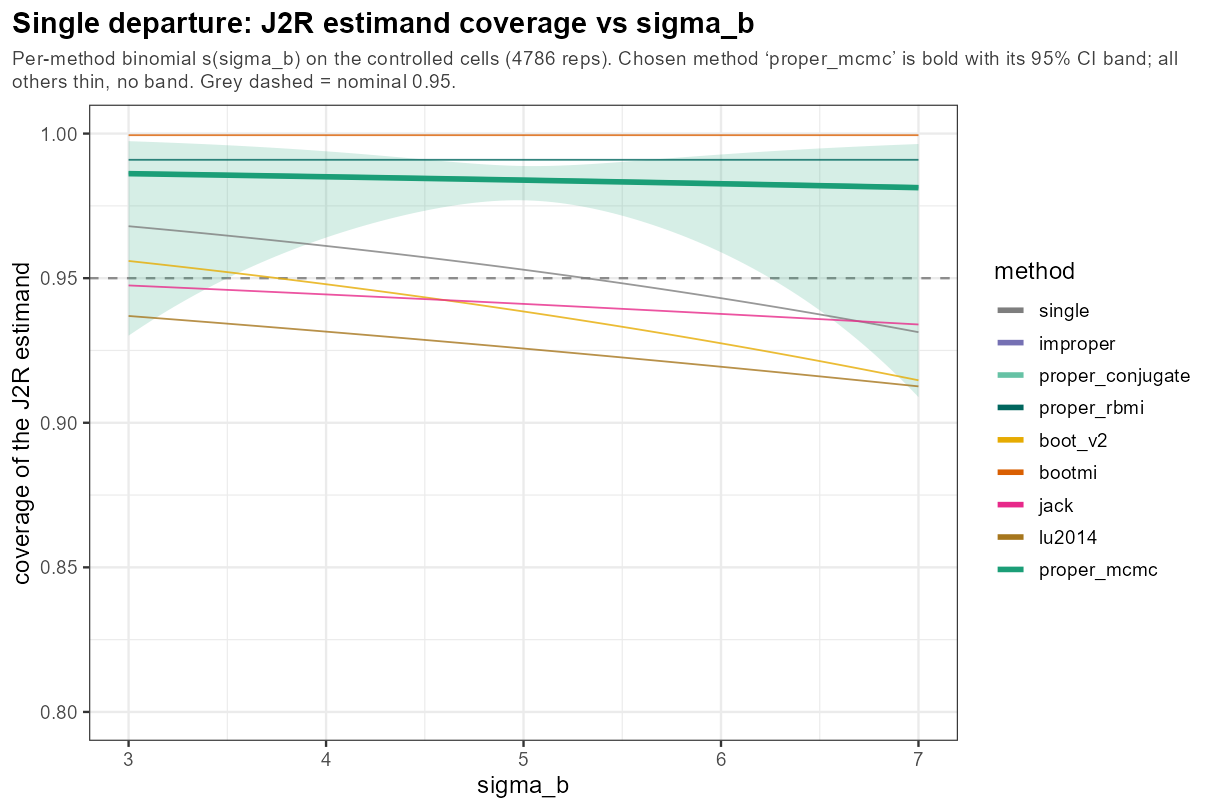
In words: the between-subject SD σ_b (how widely patients differ in overall severity) leaves coverage essentially flat — benign.
5.6 One knob: residual SD
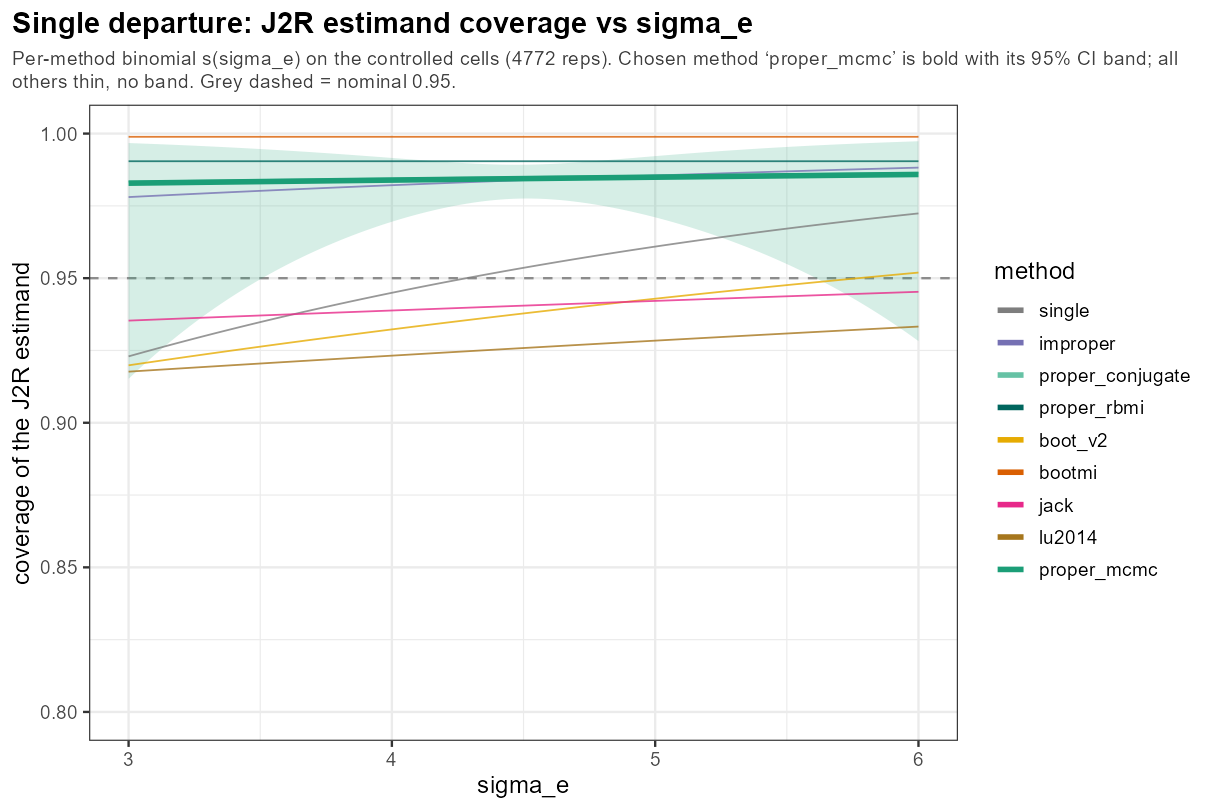
In words: the residual SD σ_e (visit-to-visit noise around a patient’s own curve) leaves coverage essentially flat — benign.
5.6 One knob: AR(1) correlation
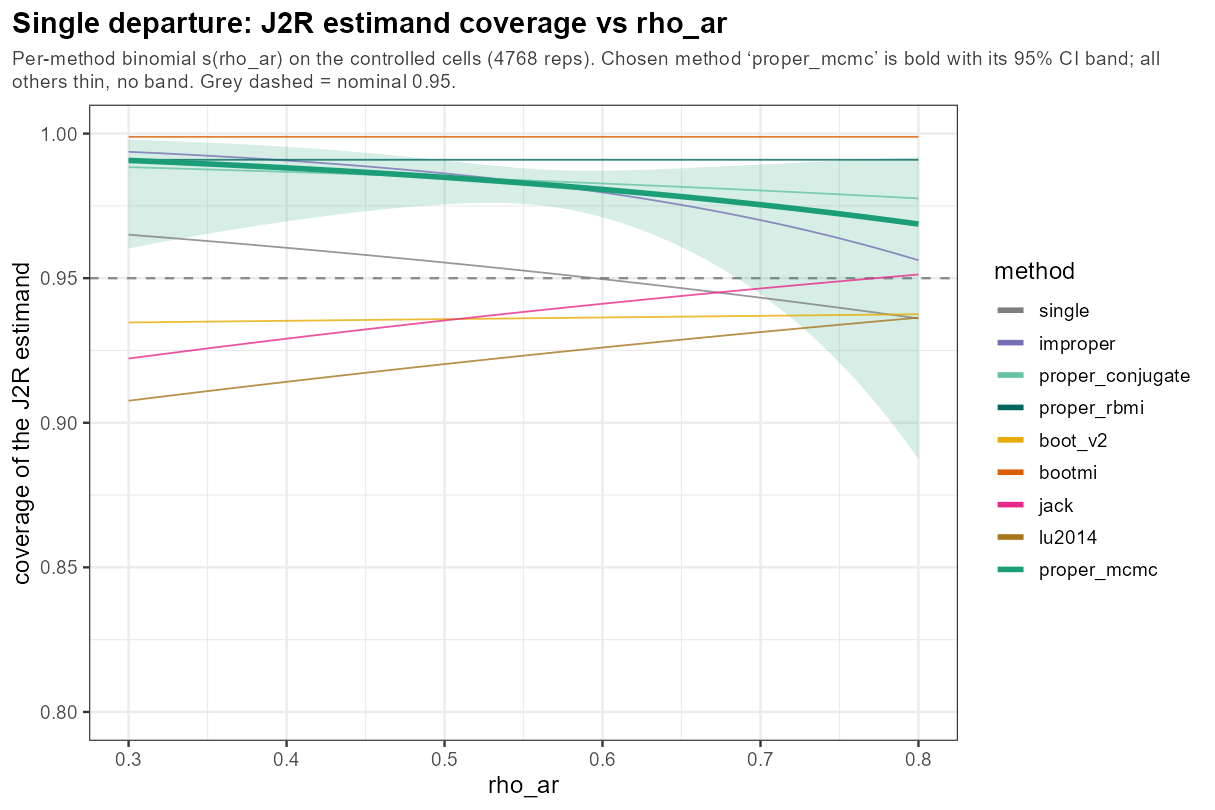
In words: the AR(1) correlation ρ — how much nearby visits agree — barely bends coverage across 0.3–0.8; another benign knob.
5.6 One knob: dropout rate
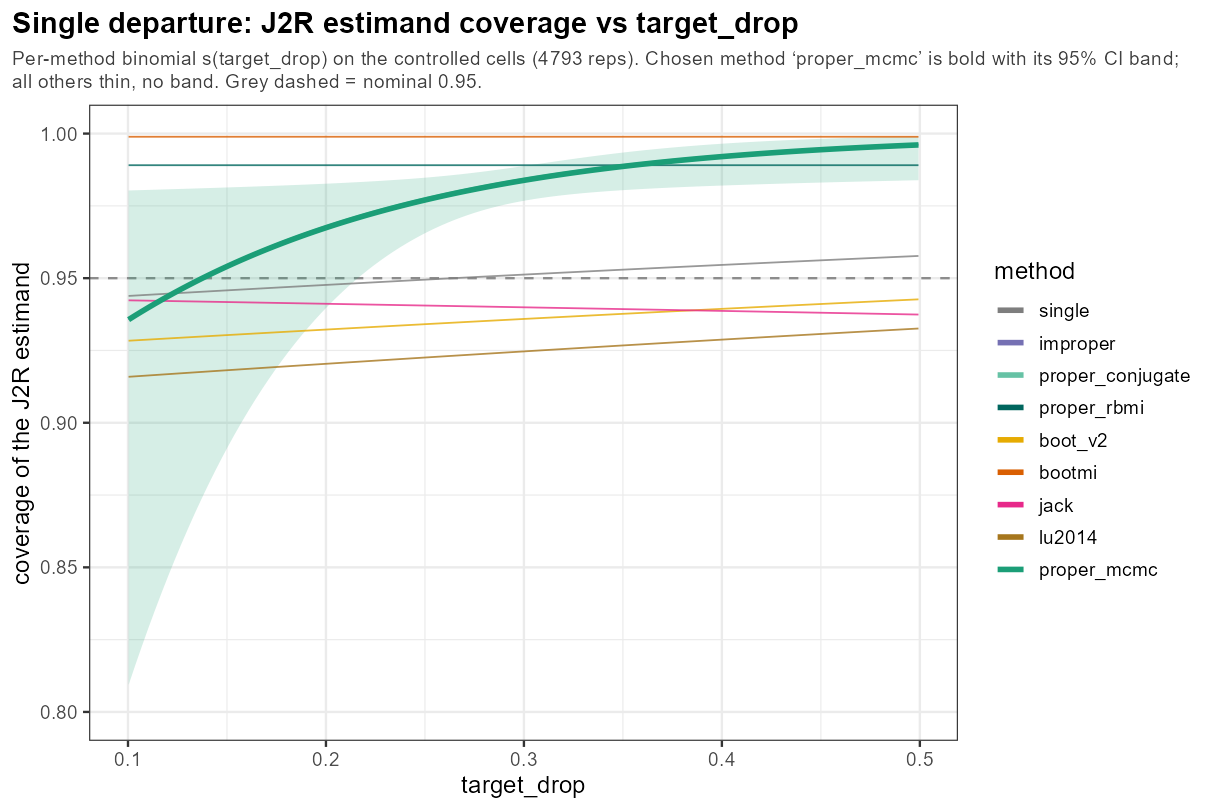
In words: the dropout rate is the one knob where even the information-anchored methods slip below 0.95 — at low dropout, when little is imputed, the J2R estimand is hardest to cover and the proper methods dip to ~0.94, climbing to over-coverage as dropout grows; the frequentist intervals sit lower still throughout.
5.6 One knob: intermittent missingness
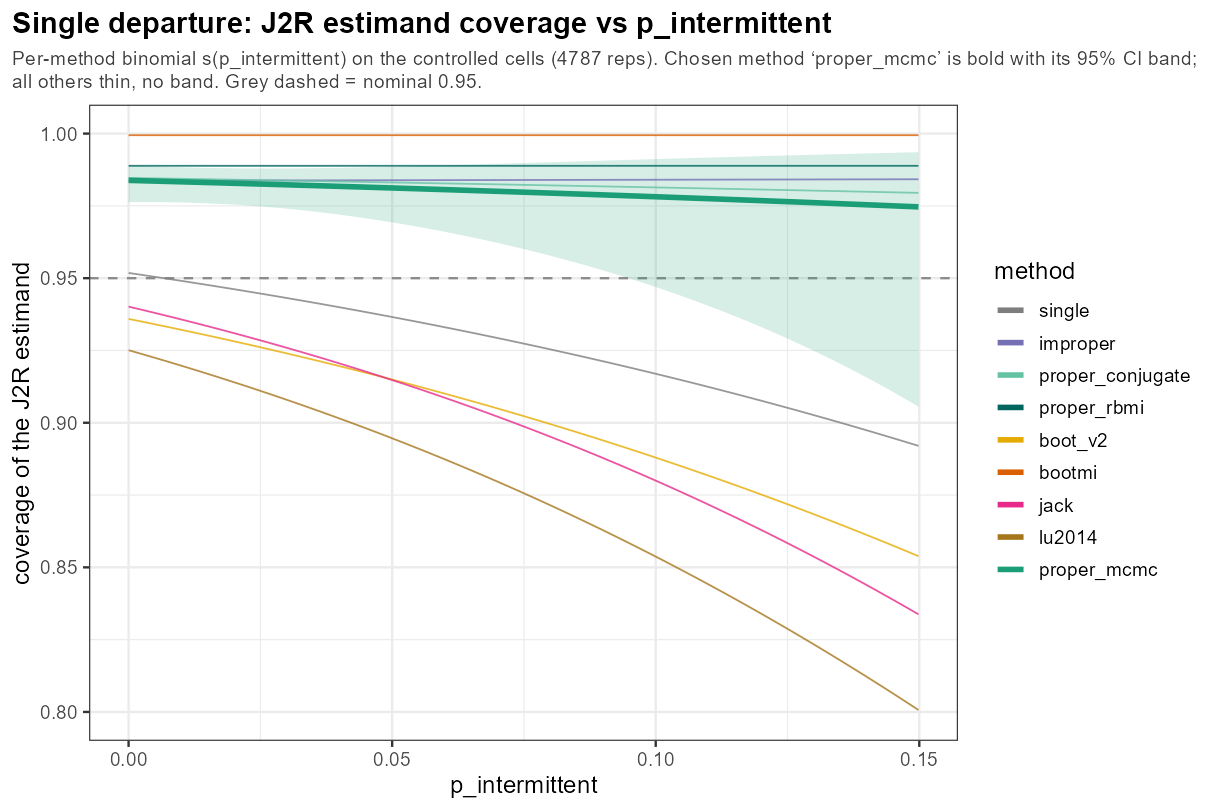
In words: intermittent missingness — isolated interior gaps rather than a clean tail — erodes the frequentist methods the most (toward ~0.85), the δ-scope-sensitive knob, while the proper methods hold.
5.8 The regret matrix (cont’d)
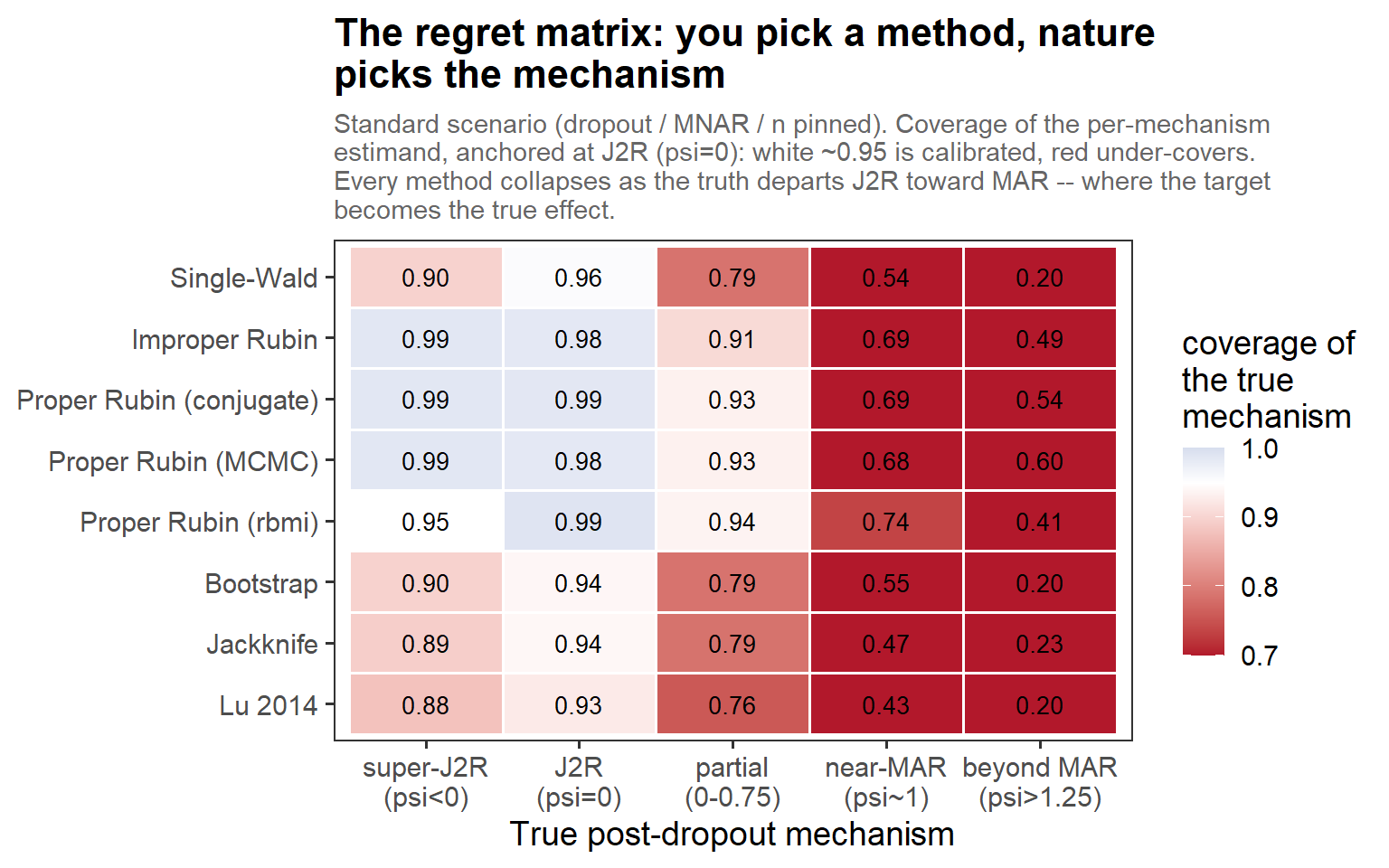
In words: nuisances pinned at the standard scenario, so each column is a clean cut of the true mechanism. There are calibrated islands at the J2R column (ψ = 0) — the three proper engines agree — but every method collapses as the truth departs toward MAR, where the per-mechanism target is the true effect. No row is blur everywhere.
5.8 At the J2R estimand, under stress
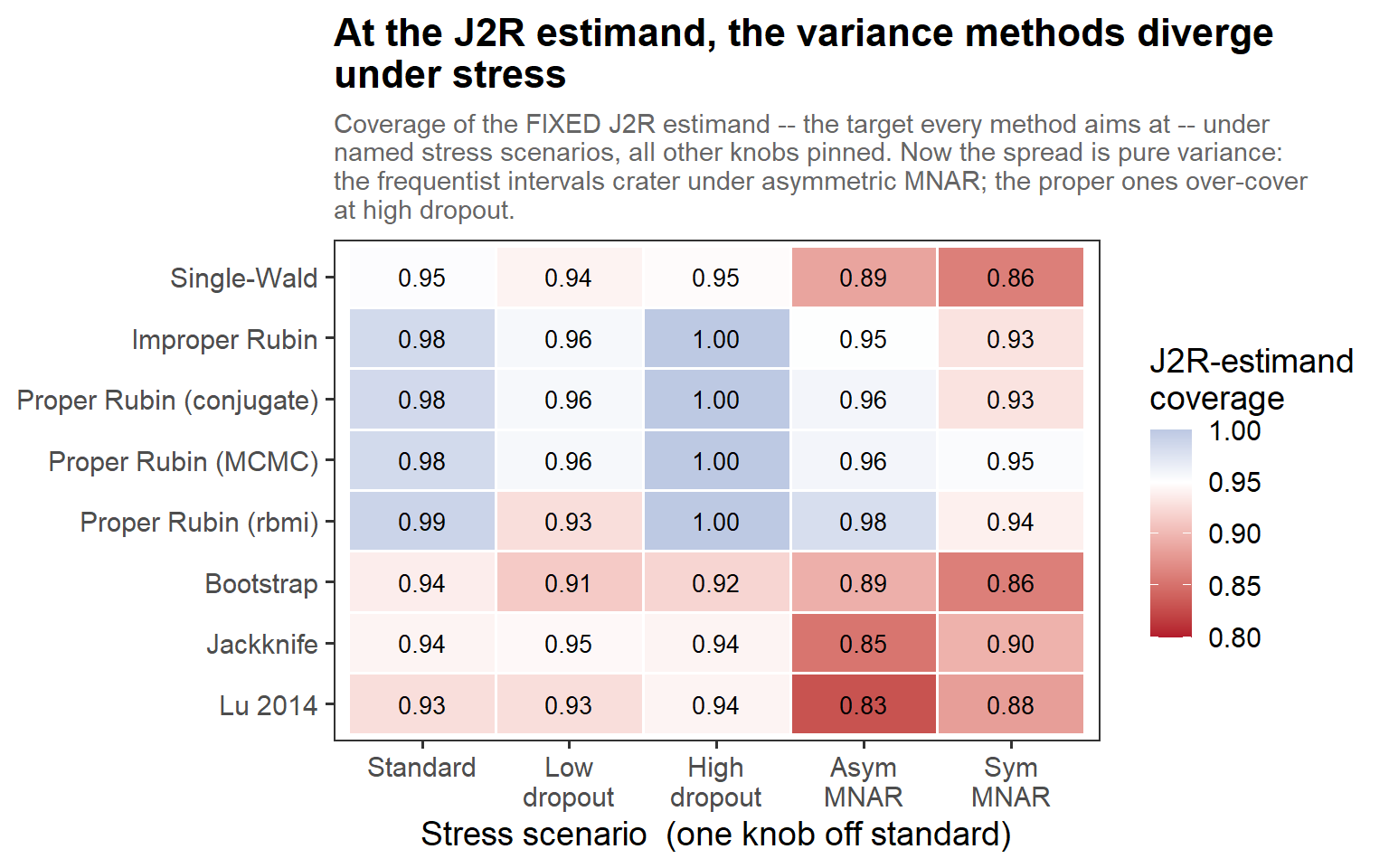
In words: the matrix above fixed the target (ψ); here we move the stressor instead, so the spread is pure variance. The frequentist intervals (bootstrap, jackknife, Lu) crater under asymmetric MNAR (~0.83–0.89), while the information-anchored proper engines hold (~0.96–0.98); at high dropout the proper ones tip into over-coverage (1.00). Same nine methods, two failure modes — bias on the left matrix, variance on this one.
5.9 The highest coverage is not the best method (cont’d)
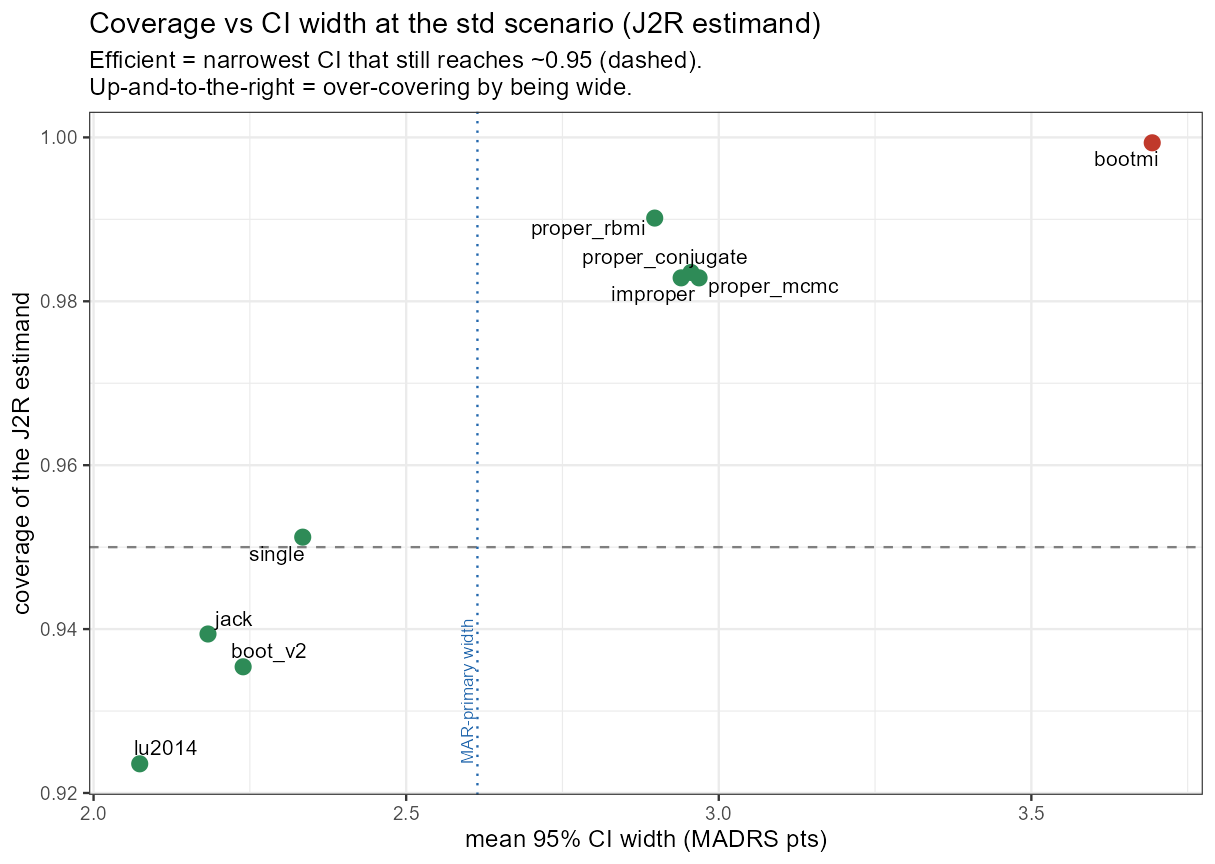
5.9 The highest coverage is not the best method (cont’d)
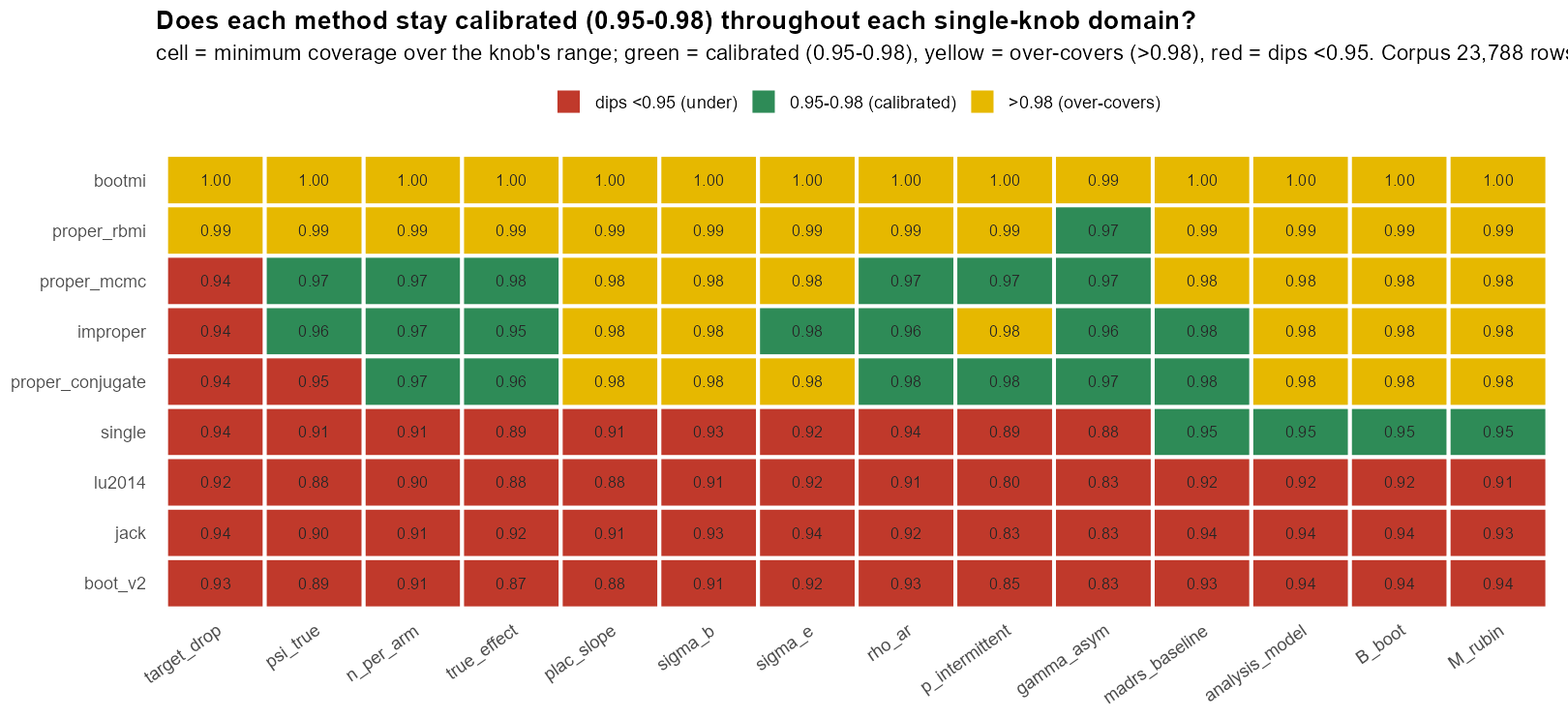
In words: the scorecard reads in three colours — red = dips below 0.95, green = the calibrated 0.95–0.98 band, yellow = over-covers (>0.98). bootmi is yellow everywhere — it passes only by over-covering; the proper-Rubin rows are mostly yellow (slipping red only at the dropout extremes); the frequentist rows are red. “Passing” this scorecard mostly means over-covering, not being calibrated.
6.2 The δ-sweep
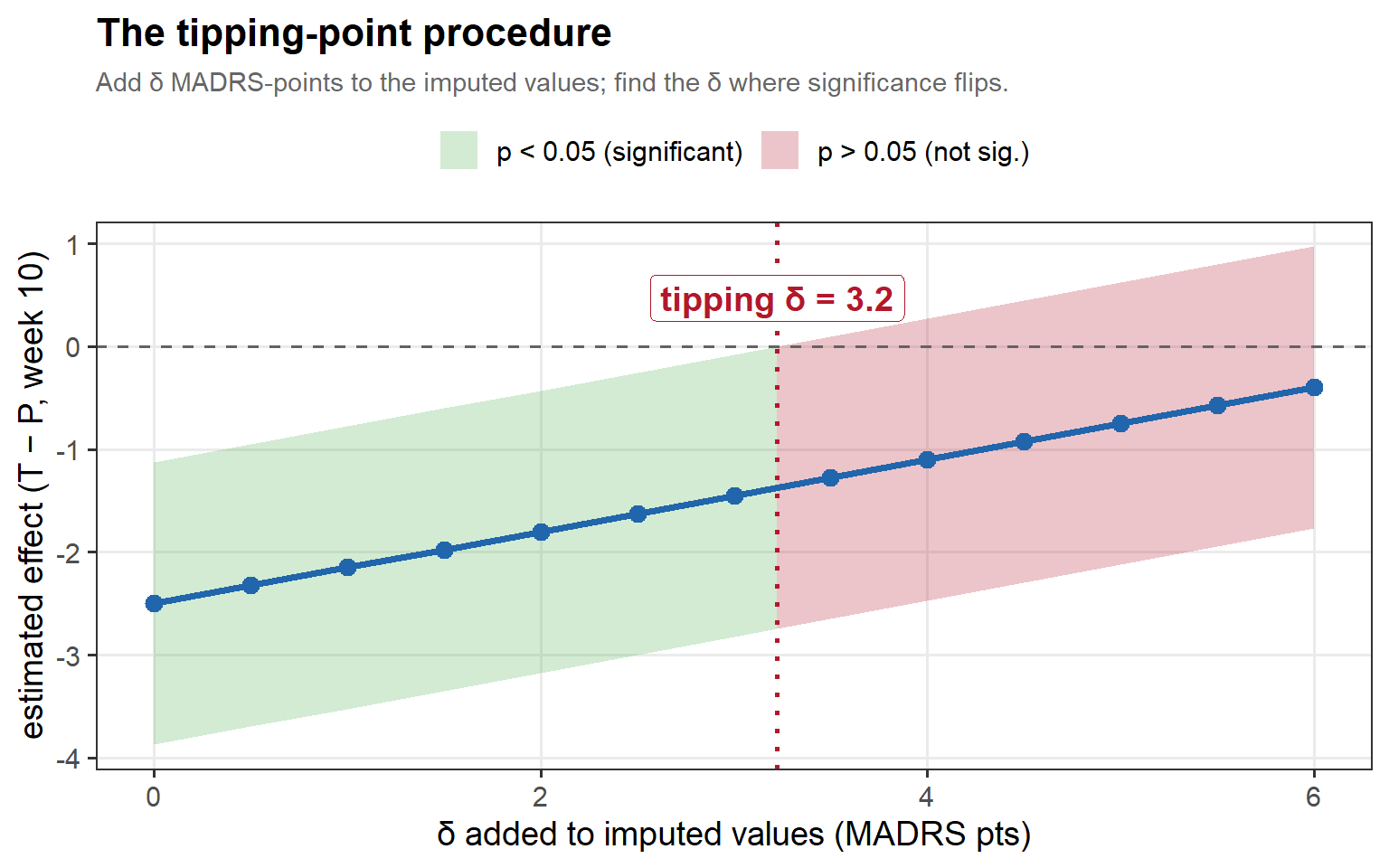
In words: as we add δ, the estimate is dragged toward the null and the confidence band climbs through zero; the tipping δ (red) is the first point at which the interval can no longer exclude no-effect. The wider the cushion before that line, the more robust the result.
6.4 The two δ-scopes, drawn
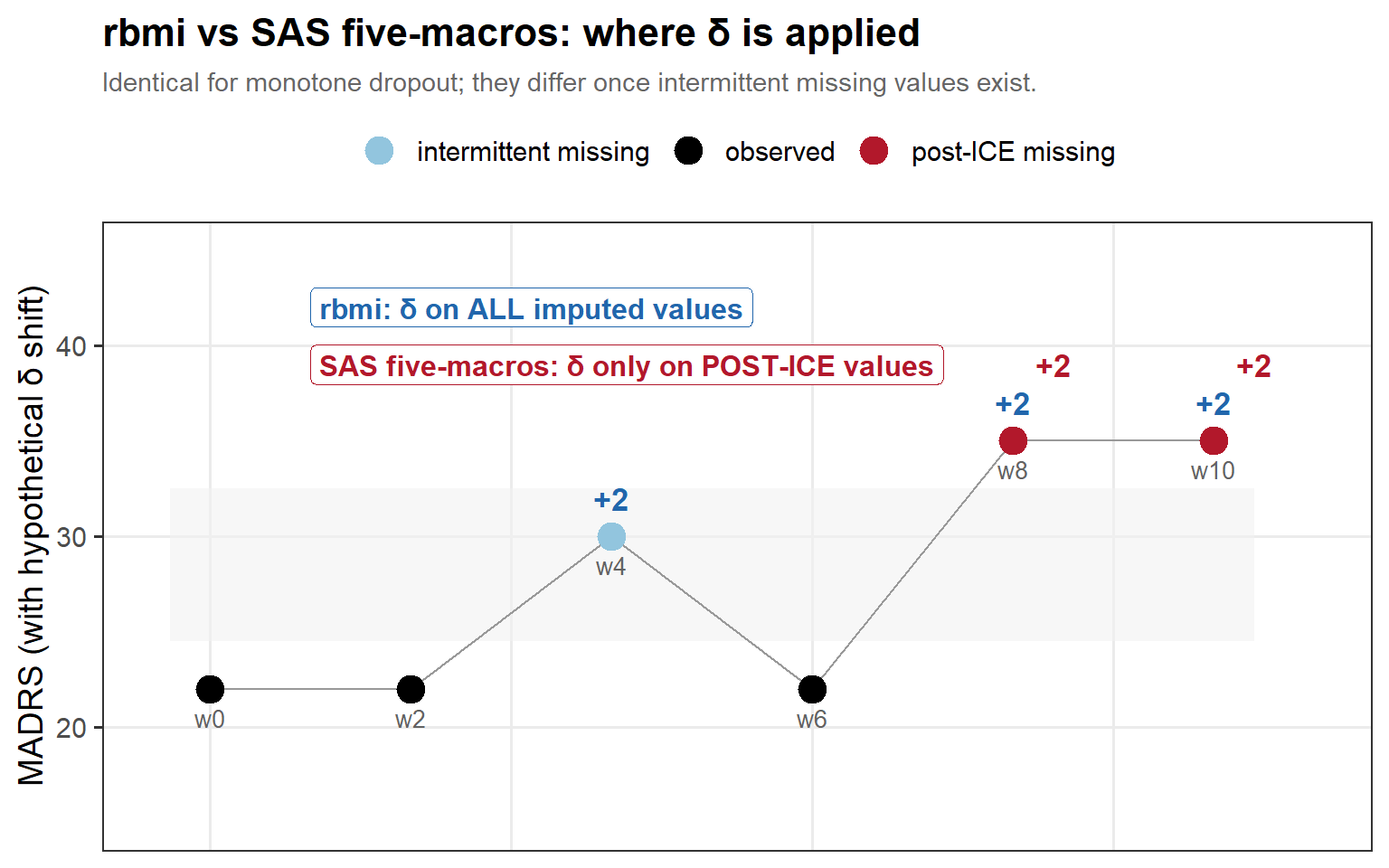
In words: for this patient, both conventions penalise the post-ICE visits (red, +δ), but only rbmi also penalises the earlier intermittent gap (the grey band) — so under intermittent missingness rbmi applies the heavier total shift and tips sooner.
6.6 A distribution of robustness margins
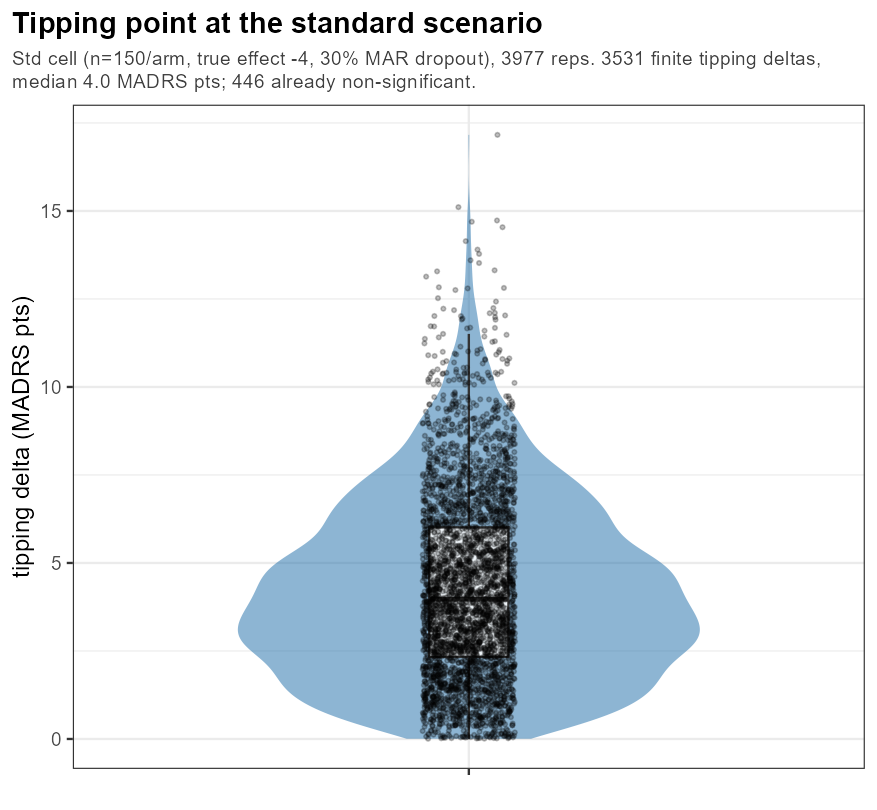
In words: even at one frozen design the tipping δ fans out across trials; the bulk sits comfortably above any plausible 2-point shift, but the lower tail is a reminder that some trials are far more fragile to MNAR than the headline average suggests.
6.8 The MNAR-connection
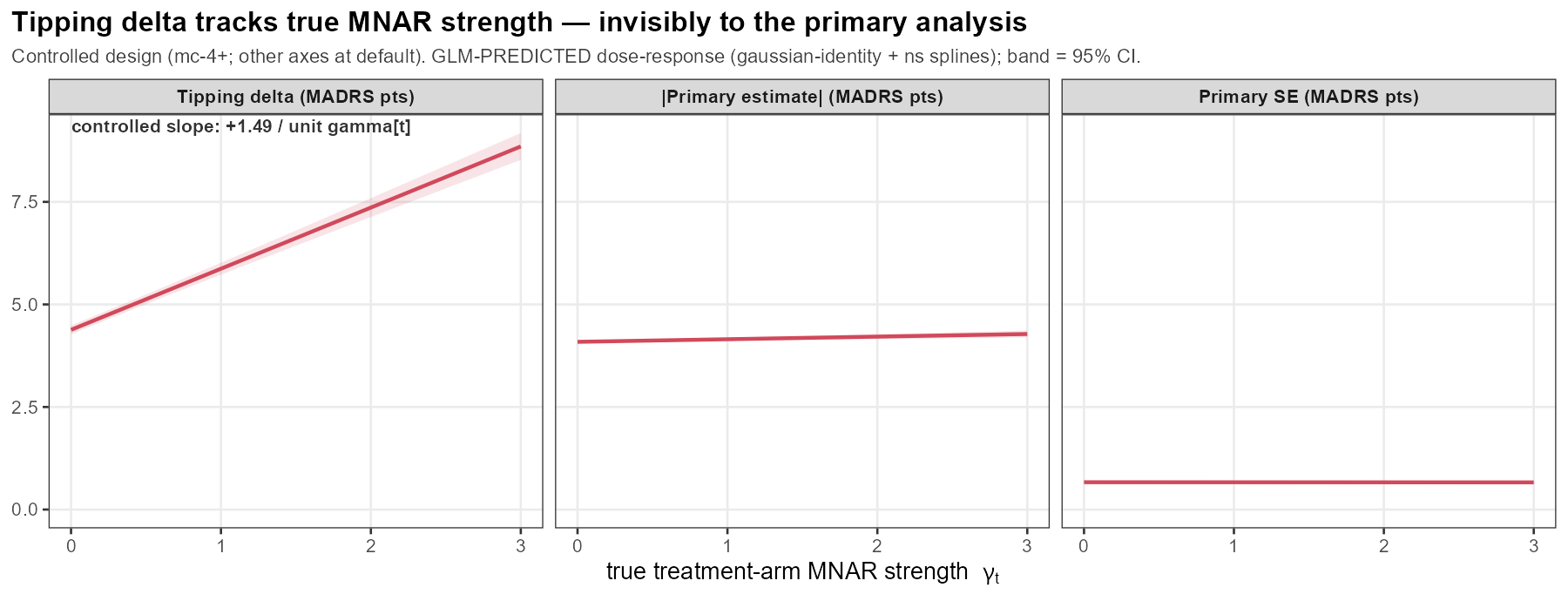
In words: as the true active-arm MNAR slope γ_t grows, the tipping δ rises]{.key}! This means that when a worrysome feature exist in the study the tipping point is falsely reassuring.